This specification defines an extensible model for managing metadata registries. The metadata artifacts can be for any purpose, such as schemas or message definitions, and the registry provides both "document" and "API" projections of the data to enable their discovery for end-user consumption or automation and tooling usage.
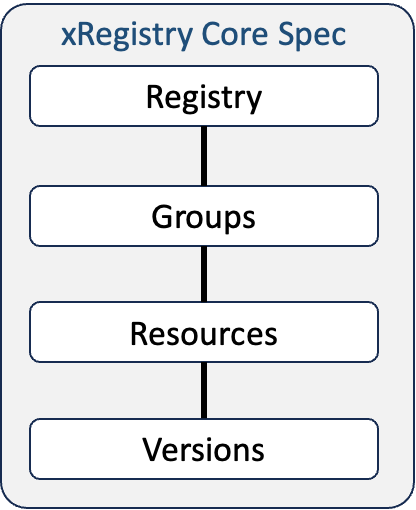
.) NotationA Registry consists of two main types of entities: Resources and Groups of such Resources.
Resources typically represent the main data of interest in the Registry, while Groups, as the name implies, allow related Resources to be arranged together under a single collection. Resources can, optionally, also be versioned if needed.
This specification defines a set of common metadata that can appear on both Resources and Groups, and allows for domain-specific extensions to be added. Additionally, this specification defines a common interaction pattern to manage, view and discover the entities in the Registry with the goal of providing an interoperable framework that will enable common tooling and automation.
See the Registry Design section for a more complete discussion of the xRegistry concepts.
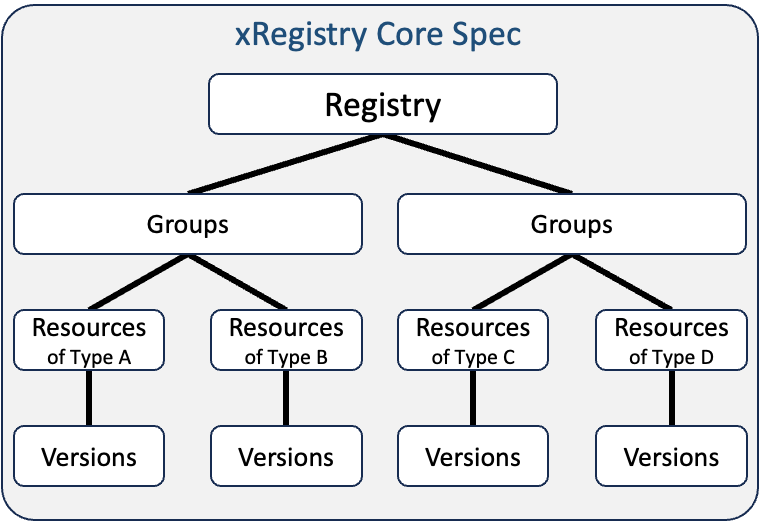
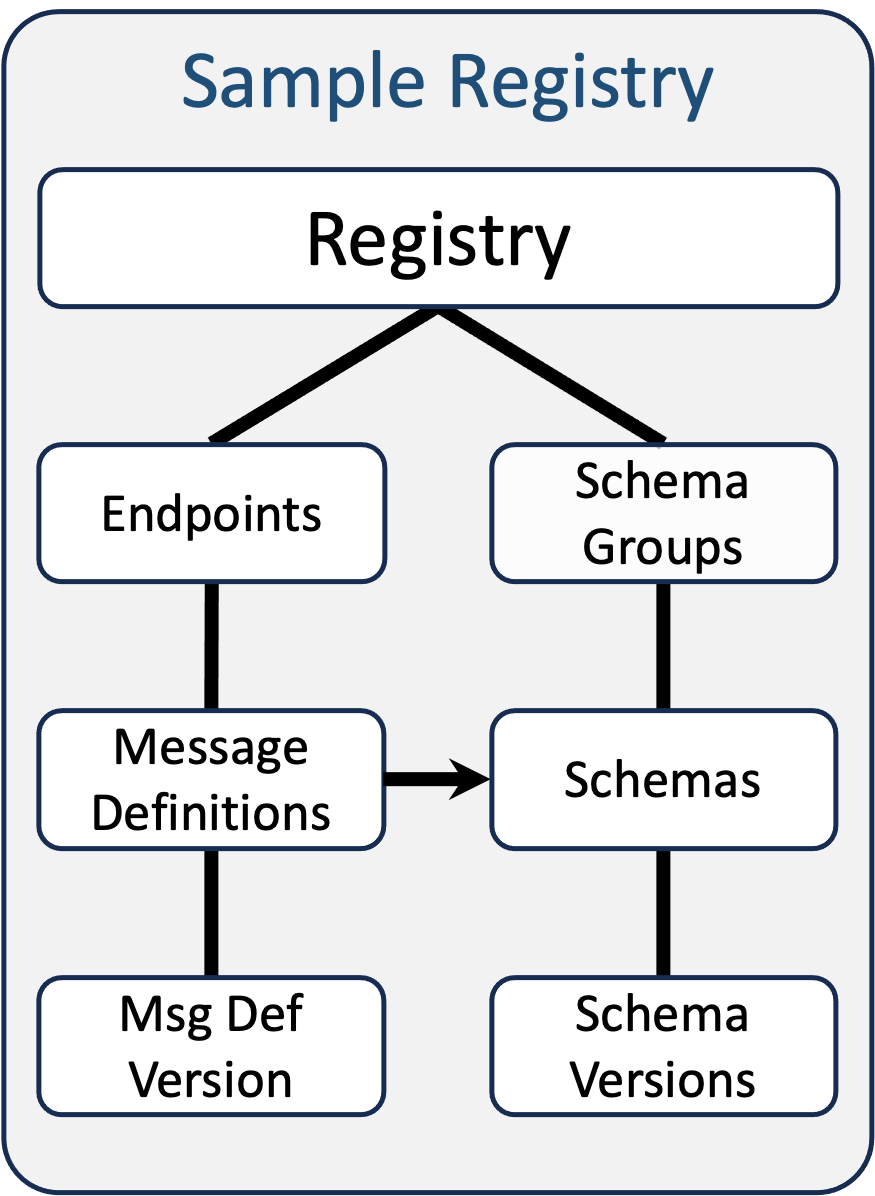
The following 3 diagrams show (from left to right):
1 - The core concepts of the Registry in its most abstract form.
2 - A Registry concept model with multiple types of Groups/Resources.
3 - A concrete sample usage of Registry that includes the use of an attribute
on "Message Definition" that is a reference to a "Schema" document - all
within the same Registry instance.
The Registry, while typically exposed as a "service", is also intended to
support exporting its data as a "document" that can then be used independently
from the service. For example, the document can be checked into a code
repository or used as input for tooling. To enable a seamless transition
between the "document" and "API" views of the data, the specification ensures
a consistent mapping between the two:

This specification is meant to be a framework from which additional specifications can be defined that expose model-specific Resources and metadata. See the Endpoint and Schema extension specifications as examples.
Additionally, this specification defines the core model and semantics of xRegistry, while secondary specifications (such as xRegistry HTTP Binding) will discuss how to expose them in a protocol-specific way.
The key words "MUST", "MUST NOT", "REQUIRED", "SHALL", "SHALL NOT", "SHOULD", "SHOULD NOT", "RECOMMENDED", "MAY", and "OPTIONAL" in this document are to be interpreted as described in RFC 2119.
For clarity, OPTIONAL attributes (specification-defined and extensions) are OPTIONAL for clients to use, but the servers' responsibility will vary. Server-unknown extension attributes MUST be silently stored in the backing datastore. Specification-defined, and server-known extension attributes, MUST generate an error if the corresponding feature is not supported or enabled. However, as with all attributes, if accepting the attribute results in a bad state (such as exceeding a size limit, or results in a security issue), then the server MAY choose to reject the request.
In the pseudo JSON format snippets ? means the preceding item is OPTIONAL,
* means the preceding item MAY appear zero or more times, and + means the
preceding item MUST appear at least once. The presence of the # character
means the remaining portion of the line is a comment. Whitespace characters in
the JSON snippets are used for readability and are not normative.
Use of <...> the notation indicates a substitutable value where that is
meant to be replaced with a runtime situational-specific value as defined by
the word/phrase in the angled brackets. For example <NAME> would be expected
to be replaced by the "name" of the item being discussed.
Use of <GROUP> and <RESOURCE> are meant to represent the singular name of a
Group and Resource type used, while <GROUPS> and <RESOURCES> are the plural
name of those respective types. Use of <SINGULAR> represents the singular
name of the entity referenced. For example, for a "schema document" Resource
type where its plural name is defined as schemas and its singular name is
defined as schema, the <SINGULAR> value would be schema.
Additionally, the following acronyms are defined:
<GID> is the <SINGULAR>id of a Group.<RID> is the <SINGULAR>id of a Resource.<VID> is the versionid of a Version of a Resource.The following are used to denote an instance of one of the associated data types (see Attributes and Extensions for more information about each data type):
<ARRAY><BOOLEAN><DECIMAL><INTEGER><MAP><OBJECT><STRING><TIMESTAMP><UINTEGER><URI><URIABSOLUTE><URIRELATIVE><URITEMPLATE><URL><URLABSOLUTE><URLRELATIVE><XID><XIDTYPE><TYPE> - one of the allowable data type names (MUST be in lower case)
listed in Attributes and Extensions<VALUE> - an instance of one of the above data typesThis specification defines the following terms:
The term "attribute" can be used in many different contexts. In order to avoid any potential confusion, "attributes" that are part of an xRegistry model definition are referred to as "aspects" as a way to indicate that they are also often mapped to "features" of the specification.
Groups, as the name implies, allow related Resources to be arranged together under a single collection - the Group. The reason for the grouping is not defined by this specification, so the owners of the Registry MAY choose to define (or enforce) any pattern they wish. In this sense, a Group is similar to a "directory" on a filesystem.
An additional common use for Groups is for access control. Managing access control on individual Resources, while possible, might be cumbersome, so moving it up to the Group could be a more manageable, and user-friendly, implementation choice.
A server-side implementation of this specification. Typically, the implementation would include model-specific Groups, Resources and extension attributes.
There is also a "Registry" entity which acts as the root of an xRegistry instance, under which all Groups will reside. The Registry entity itself has metadata associated with it.
Resources, typically, represent the main data of interest for the Registry. In the filesystem analogy, these would be the "files". Each Resource MUST exist under a single Group and, similar to Groups, have a set of Registry metadata. However, unlike a Group, which only has Registry metadata, each Resource MAY also have a secondary domain-specific "document" associated with it. For example, a "schema" Resource might have a "schema document" as its "document". This specification places no restriction on the type of content stored in the Resource's document. Additionally, Resources (unlike Groups) MAY be versioned.
A Version is an instance of a Resource that represents a particular state of the Resource. Each Version of a Resource has its own set of xRegistry metadata and possibly a domain-specific document associated with it. Each Resource MUST have at least one Version associated with it.
Clients MAY interact with specific Versions or with the Resource itself, which is equivalent to interacting with the Resource's "default" Version. While in many cases the "default" Version will be the "newest" Version, this specification allows for the "default" Version to be explicitly chosen and unaffected as other Versions are added or removed.
If versioning is not important for the use case in which the Resource is used, the default Version can be evolved without creating new ones.
This specification places no requirements on the lifecycle of Versions. Implementations, or users of the Registry, determine when new Versions are created, as opposed to updating existing Versions, and how many Versions are allowed per Resource type.
As discussed in the Overview section, an xRegistry consists of two main entities related to the data being managed: Groups and Resources. However, there are other concepts that make up the overall design and this section will cover them all in more detail.
Each entity type defined within the Registry will have both a plural and
singular "type name" associated with it. For example, a Schema Resource
might have schemas as its "plural" type name and schema as its "singular"
type name. This enables the appropriate name to be used based on the context
in which it appears. In the Schema Resource example, schemas would be used
when a collection of Schemas is referenced, such as in URLs (e.g.
.../schemas/myschema), while schema would be used when a single Schema
is referenced (e.g. as part of its ID name: schemaid).
An xRegistry instance, or a "Registry", can be thought of as a single rooted tree of entities as shown in the "xRegistry Core Spec" diagram in the Overview section. At the root is the Registry entity itself. This entity is also meant to serve a few other key purposes:
schemagroups that has schemas as the
Resources within those Groups. All xRegistry protocol specifications
(e.g. http(./http.md) MUST define at least one REQUIRED mechanism by
which the model can be retrieved.Below the Registry, Groups serve as logical collections of related Resources. Each Group exposes the same high-level metadata as the Registry and supports user-defined extensions attributes. In practice, Group often act as lightweight "directories" for Resources, but they can also encapsulate rich, domain-specific data via custom extensions (see Endpoint as an example).
A Resource entity in the Registry holds one or more Versions of metadata, and optionally a domain-specific document. If a Resource holds multiple Versions, those can be organized with compatibility policies and lineage. Each Resource always has a default Version corresponding to one of the available Versions that is indirectly accessed when interacting with the Resource. All held Versions can be accessed directly through the Versions collection.
Each Version of a Resource MAY be defined to have a "domain-specific" document
associated with it. These documents MAY be stored within the Version as an
attribute, or MAY be stored external to the Version and a URL to its location
will be stored within the Version instead. This model design choice is
specified via the
hasdocument aspect
of the Resource type's model definition.
Typically, the domain-specific document will be used when a pre-existing document definition already exists and an xRegistry is used as the mechanism to expose those documents in a consistent and interoperable way. For example, the Schema Registry only has a few xRegistry Resource extension attributes defined because most of the data of interest will be in the Schema documents associated with the Resources.
See Resource Metadata vs Resource Document for more information.
This specification is designed such that clients can choose how they want the data from a server to be returned. There are three main "views" that clients can choose from:
In this view, clients retrieving all (or part) of the Registry hierarchy as a single document. In this case, nested (or child) entities MAY be "inlined" into the retrieved document such that the need for secondary interactions with the server is reduced.
This is often used for cases where the documents are stored in some document storage system (e.g. Github), or as input into local tooling that expects all of the relevant data to be stored locally on disk.
See the HTTP GET /export operation for one way to
generate this view.
In this view, it is assumed that the client is interested in an interactive discovery and retrieval of the Registry data. Most often clients will "walk" the hierarchy of entities by following the references (links) provided within the serialization of each entity to find the data of interest. As such, in this view, each entity is, by default, retrieved from the server via independent "read" operations.
A query without the use of the Doc flag, is an example of how to generate this view.
This is a variant of the "API view". In situations where the Registry data is stored as independent files either on disk, or in some other object storage system, the client might want to avoid the duplication of information that, by default, a server might generate. For example, they might not want the default Version's metadata to be visible in the owning Resource's serialization.
Documents generated in this view are often stored locally such that they can be managed independently for use in tooling or stored in some source-code control system (e.g. Github) to minimize the number of conflicting edits between users in a very fluid environment.
A query with the use of the Doc flag, is an example of how to generate this view.
This specification provides the mechanisms to allow for users to choose the best "view" for their needs. Regardless of the view, the design allows for the retrieved data to then be used as input into an xRegistry server.
One of the goals of xRegistry is to be as broadly supported as possible. Requiring all xRegistry endpoints to support the full range of APIs of a particular protocol binding might not be feasible in all cases. In particular, there might be cases where someone wishes to host a read-only xRegistry server and therefore the write operations or advanced features (such as inlining or filtering) might not be available. In those cases, simple file serving HTTP servers, such as blob stores, ought to be sufficient, and requiring support for flag/query parameters and other advanced features (that could require custom code) might not always be possible.
To support these simple (no-code) scenarios, this specification (and the protocol binding specifications) are written such that the support for the various operations and features (e.g. request flags) will typically be marked as OPTIONAL (often with a "SHOULD" RFC2119 key word). However, it is STRONGLY RECOMMENDED that full servers support as many of the operations and features/flags when possible to enable a better user experience, and increase interoperability.
See the HTTP Binding for more details on how this might manifest itself for HTTP servers.
This specification defines the core model and semantics of an xRegistry server implementation without regard to what protocol might be used to interact with it.
In general, all interactions with a server SHOULD be OPTIONAL and dictated by the specific needs of the environment in which it is being used. However, it is STRONGLY RECOMMENDED that servers support the "read" operations, and in particular the ability to retrieve the "capabilities" and "model" such that tooling can then dynamically discover the remaining data within the Registry.
Implementations MAY choose to incorporate authentication and/or authorization mechanisms as needed, but those are out of scope for this specification.
This specification defines the JSON serialization of the xRegistry entities. Alternative serialization formats MAY be defined.
For easy reference, the JSON serialization of a Registry adheres to this form:
{
"specversion": "<STRING>",
"registryid": "<STRING>",
"self": "<URL>",
"shortself": "<URL>", ?
"xid": "<XID>",
"epoch": <UINTEGER>,
"name": "<STRING>", ?
"description": "<STRING>", ?
"documentation": "<URL>", ?
"icon": "<URL>", ?
"labels": { "<STRING>": "<STRING>" * }, ?
"createdat": "<TIMESTAMP>",
"modifiedat": "<TIMESTAMP>",
"capabilities": { # Supported capabilities/options
"available": {
"capabilities": { "mutable": <BOOLEAN> }, ?
"capabilitiesoffered": { "mutable": <BOOLEAN> }, ?
"entities": { "mutable": <BOOLEAN> },
"export": { "mutable": false }, ?
"model": { "mutable": false }, ?
"modelsource": { "mutable": <BOOLEAN> } ?
},
"compatibilities": {
"<STRING>" : [ "<STRING>" * ] *
}, ?
"flags": [ # e.g. Query parameters
"binary",? "collections",? "doc",? "epoch",? "filter",? "ignore",?
"inline",? "setdefaultversionid",? "sort",? "specversion",?
"<STRING>" *
],
"formats": [ "<STRING" * ], ?
"ignores": [ "capabilities",? "defaultversionid",? "defaultversionsticky",?
"id",? "epoch",? "modelsource",? "readonly"? ],
"pagination": <BOOLEAN>, ?
"shortself": <BOOLEAN>, ?
"specversions": [ "1.0-rc3", "<STRING>"* ], ?
"versionmodes": [ "manual", "createdat",? "modifiedat",? "semver",?
"<STRING>"* ], ?
"<STRING>": ... * # Extension capabilities
}, ?
"model": { # Full model. Only if inlined
"description": "<STRING>", ?
"documentation": "<URL>", ?
"labels": { "<STRING>": "<STRING>" * }, ?
"attributes": { # Registry-level attributes/extensions
"<STRING>": { # Attribute name (case-sensitive)
"name": "<STRING>", # Same as attribute's key
"type": "<TYPE>", # string, decimal, array, object, ...
"target": "<XIDTYPE>", ? # If "type" is "xid" or "url"
"namecharset": "<STRING>", ? # If "type" is "object"
"description": "<STRING>", ?
"enum": [ <VALUE> * ], ? # Array of scalars of type `"type"`
"strict": <BOOLEAN>, ? # Just "enum" values? Default=true
"matchcase": <BOOLEAN>, ? # Strings case-sensitive? Def=false
"matchversions": <BOOLEAN>, ? # Same for all Versions? Def=false
"readonly": <BOOLEAN>, ? # From client's POV. Default=false
"immutable": <BOOLEAN>, ? # Once set, can't change. Default=false
"required": <BOOLEAN>, ? # Default=false
"default": <VALUE>, ? # Scalar attribute's default value
"attributes": { ... }, ? # If "type" above is object
"item": { # If "type" above is map,array
"type": "<TYPE>", ? # map value type, or array type
"target": "<XIDTYPE>", ? # If this item "type" is xid/url
"namecharset": "<STRING>", ? # If this item "type" is object
"attributes": { ... }, ? # If this item "type" is object
"item": { ... } ? # If this item "type" is map,array
} ?
"ifvalues": { # If "type" is scalar
"<STRING>": { # Possible attribute value
"siblingattributes": { ... } # See "attributes" above
} *
} ?
} *
},
"groups": {
"<STRING>": { # Key=plural name, e.g. "endpoints"
"plural": "<STRING>", # e.g. "endpoints"
"singular": "<STRING>", # e.g. "endpoint"
"description": "<STRING>", ?
"documentation": "<URL>", ?
"icon": "<URL>", ?
"labels": { "<STRING>": "<STRING>" * }, ?
"modelversion": "<STRING>", ? # Version of the group model
"modelcompatiblewith": "<URI>", ? # Statement of compatibility
"attributes": { ... }, ? # Group-level attributes/extensions
"ximportresources": [ "<XIDTYPE>", * ], ? # Include these Resources,
# only for "modelsource"
"resources": {
"<STRING>": { # Key=plural name, e.g. "messages"
"plural": "<STRING>", # e.g. "messages"
"singular": "<STRING>", # e.g. "message"
"description": "<STRING>", ?
"documentation": "<URL>", ?
"icon": "<URL>", ?
"labels": { "<STRING>": "<STRING>" * }, ?
"modelversion": "<STRING>", ? # Version of the resource model
"modelcompatiblewith": "<URI>", ? # Statement of compatibility
"maxversions": <UINTEGER>, ? # Num Vers(>=0). Default=0(unlimited)
"setversionid": <BOOLEAN>, ? # vid settable? Default=true
"hasdocument": <BOOLEAN>, ? # Has separate document. Default=true
"versionmode": "<STRING>", ? # Ancestor processing algorithm
"singleversionroot": <BOOLEAN>, ? # Default=false"
"validateformat": <BOOLEAN>, ? # Check version format compliance. Default=false
"validatecompatibility": <BOOLEAN>, ? # Check version compatibility. Default=false
"strictvalidation": <BOOLEAN>, ? # Block unknown format/compat. Default=false
"typemap": <MAP>, ? # contenttype mappings
"attributes": { ... }, ? # Version attributes/extensions
"resourceattributes": { ... }, ? # Resource attributes/extensions
"metaattributes": { ... } ? # Meta attributes/extensions
} *
} ?
} *
} ?
}, ?
"modelsource": { ... }, ? # Input model, if inlined
# Repeat for each Group type
"<GROUPS>url": "<URL>", # e.g. "endpointsurl"
"<GROUPS>count": <UINTEGER>, # e.g. "endpointscount"
"<GROUPS>": { # Only if inlined
"<KEY>": { # Key=the Group ID
"<GROUP>id": "<STRING>", # The Group ID
"self": "<URL>",
"shortself": "<URL>", ?
"xid": "<XID>",
"epoch": <UINTEGER>,
"name": "<STRING>", ?
"description": "<STRING>", ?
"documentation": "<URL>", ?
"icon": "<URL>", ?
"labels": { "<STRING>": "<STRING>" * }, ?
"createdat": "<TIMESTAMP>",
"modifiedat": "<TIMESTAMP>",
"deprecated": {
"effective": "<TIMESTAMP>", ?
"removal": "<TIMESTAMP>", ?
"alternative": "<URL>", ?
"documentation": "<URL>"?
}, ?
"constraints": {
"<RESOURCES>.<PATH>": { # Resource-plural + attr path
"default": <VALUE>, ? # Group specific default
"enum": [ <VALUE> * ], ? # Allowed subset of values
"equals": "<PATH>" ? # Matching Group attribute path
} *
}, ?
# Repeat for each Resource type in the Group
"<RESOURCES>url": "<URL>", # e.g. "messagesurl"
"<RESOURCES>count": <UINTEGER>, # e.g. "messagescount"
"<RESOURCES>": { # Only if inlined
"<KEY>": { # The Resource ID
"<RESOURCE>id": "<STRING>",
"versionid": "<STRING>", # Default Version's ID
"self": "<URL>", # Resource URL, not Version
"shortself": "<URL>", ?
"xid": "<XID>", # Resource XID, not Version
"epoch": <UINTEGER>, # Start of default Ver attrs
"name": "<STRING>", ?
"isdefault": true,
"description": "<STRING>", ?
"documentation": "<URL>", ?
"icon": "<URL>", ?
"labels": { "<STRING>": "<STRING>" * }, ?
"createdat": "<TIMESTAMP>",
"modifiedat": "<TIMESTAMP>",
"ancestorid": "<STRING>", # Ancestor's versionid
"contenttype": "<STRING>", ? # Add default Ver extensions
"format": "<STRING>", ?
"formatvalidated": <BOOLEAN>, ?
"formatvalidatedreason": "<STRING>", ?
"compatibilityvalidated": <BOOLEAN>, ?
"compatibilityvalidatedreason": "<STRING>", ?
"<RESOURCE>url": "<URL>", ? # If not local
"<RESOURCE>": ... Resource document ..., ? # If local & inlined & JSON
"<RESOURCE>base64": "<STRING>", ? # If local & inlined & ~JSON
# End of default Ver attrs
# Resource-level helper attributes
"metaurl": "<URL>",
"meta": { # Only if inlined
"<RESOURCE>id": "<STRING>",
"self": "<URL>", # URL to "meta" object
"shortself": "<URL>", ?
"xid": "<XID>",
"xref": "<XID>", ? # xid of linked Resource
"epoch": <UINTEGER>, # Resource's
"labels": { "<STRING>": "<STRING>" * }, ? # Resource's
"createdat": "<TIMESTAMP>", # Resource's
"modifiedat": "<TIMESTAMP>", # Resource's
"readonly": <BOOLEAN>, # Default=false
"compatibility": "<STRING>", ?
"deprecated": {
"effective": "<TIMESTAMP>", ?
"removal": "<TIMESTAMP>", ?
"alternative": "<URL>", ?
"documentation": "<URL>"?
}, ?
"defaultversionid": "<STRING>",
"defaultversionurl": "<URL>",
"defaultversionsticky": <BOOLEAN> ? # Default=false
}, ?
"versionsurl": "<URL>",
"versionscount": <UINTEGER>,
"versions": { # Only if inlined
"<KEY>": { # The Version's versionid
"<RESOURCE>id": "<STRING>", # The Resource ID
"versionid": "<STRING>", # The Version ID
"self": "<URL>", # Version URL
"shortself": "<URL>", ?
"xid": "<XID>",
"epoch": <UINTEGER>, # Version's epoch
"name": "<STRING>", ?
"isdefault": <BOOLEAN>, # Default=false
"description": "<STRING>", ?
"documentation": "<URL>", ?
"icon": "<URL>", ?
"labels": { "<STRING>": "<STRING>" * }, ? # Version's labels
"createdat": "<TIMESTAMP>",
"modifiedat": "<TIMESTAMP>",
"ancestorid": "<STRING>", # Ancestor's versionid
"contenttype": "<STRING>", ?
"format": "<STRING>", ?
"formatvalidated": <BOOLEAN>, ?
"formatvalidatedreason": "<STRING>", ?
"compatibilityvalidated": <BOOLEAN>, ?
"compatibilityvalidatedreason": "<STRING>", ?
"<RESOURCE>url": "<URL>", ? # If not local
"<RESOURCE>": ... Resource document ..., ? # If inlined & JSON
"<RESOURCE>base64": "<STRING>" ? # If inlined & ~JSON
} *
} ?
} *
} ?
} *
} ?
}
See the Includes in the xRegistry Model
Data
section for use of the $include(s) directives in modelsource.
If there is an issue with reading or parsing the data provided to the server, then an error (parsing_data) MUST be generated.
In general, if a server is unable to retrieve all of the data intended to be sent in a response, then an error (data_retrieval_error) MUST be generated and the request rejected without any changes being made. However, it is permissible for a server to attempt some creative processing. For example, if while processing a query the server can only retrieve half of the entities to be returned at the current point in time, then it could return those with an indication of there being more (via use of a pagination type of specification). Then during the next query request it could return the remainder of the data - or an error if it is still not available to retrieve the data. Note that if an entity is to be sent, then it MUST be serialized in its entirety (all attributes, and requested child entities) or an error MUST be generated.
There might be situations where someone will do a query to retrieve data
from a Registry, and then do an update operation to a Registry with that data.
Depending on the use case, they might not want some of the retrieved data
to be applied during the update. For example, they might not want the
epoch validation checking to occur. Rather than forcing the user to edit
the data to remove the potentially problematic attributes, a client MAY use
the Ignore Flag to ignore some of the data in the incoming
request.
$schema keyword 🔗Any JSON xRegistry metadata message that represents a single entity (i.e. not a map) MAY include a top-level "$schema" attribute that points to a JSON Schema document that describes the message contents. These notations can be used or ignored by receivers of these messages. There is no requirement for implementations of this specification to persist these values, to include them in responses or to use this information.
To reduce the number of interactions needed when creating an entity, all
nonexisting parent entities specified as part of <PATH> to the entity MUST
be implicitly created. Each of those entities MUST be created with the
appropriate <SINGULAR>id specified in the <PATH>. If any of those
entities have REQUIRED attributes, then they cannot be implicitly created, and
would need to be created directly. This also means that the creation of the
original entity would fail and generate an error
(required_attribute_missing) for the
appropriate parent entity.
xRegistry defines a set of events that SHOULD be generated when changes are made to the entities within a Registry. See the xRegistry Events specification for more information.
In summary, xRegistry is designed to be a tree of entities that, along with its extensible metadata model, can support categorizing, managing and exposing a wide range of metadata allowing for a dynamically discoverable, yet interoperable, programmatic access via what might otherwise be a domain-specific set of APIs.
The following sections will define the technical details of those xRegistry entities.
This section defines the common Registry metadata model, its semantics and protocol-independent processing rules. It is an explicit goal for this specification that metadata can be created and managed in files in a file system, for instance in a Git repository, and also managed in a Registry service that implements an xRegistry protocol binding, such as the HTTP Binding.
For instance, during development of a module, the metadata about the events raised by the modules will best be managed in a file that resides alongside the module's source code. When the module is ready to be deployed into a concrete system, the metadata about the events will be registered in a Registry service along with the endpoints where those events can be subscribed to or consumed from, and which allows discovery of the endpoints and all related metadata by other systems at runtime.
Therefore, the hierarchical structure of the Registry Model is defined in such a way that it can be represented in one or more files, including but not limited to JSON, or via the entity graph of an API.
In the remainder of this specification, in particular when defining the attributes of the Registry entities, the terms "document view" or "API view" will be used to indicate whether the serialization of the entity in a response is meant for use as a stand-alone document or as part of an API message exchange. The most notable differences are that in document view:
versions collection will most
likely include the "default" Version, so duplicating that information is
redundant.Most of these differences are to make it easier for tooling to use the "stand-alone" document view of the Registry. For a complete list of the differences in "document view" see the Doc Flag flag.
Note that "document view" only refers to response messages when the Doc Flag is used. There is no "document view" concept for requests. However, "document view" responses are designed such that they can be used in request messages as they still convey the same information as an "API view" response.
Unless otherwise stated in a protocol binding specification, if the processing of a request fails (even during the generation of the response) then an error MUST be generated and the entire request MUST be undone. See the Error Processing section for more information.
This specification does not address many of the details that would need to be added for a live instance of a service; as often times these aspects are very specific to the environment in which the service is running. For example, this specification does not address authentication or authorization levels of users, nor how to securely protect the APIs, clients or servers, from attacks. Implementations of this specification are expected to add these various features as needed.
Additionally, implementations MAY choose to customize the data and behavior on a per-user basis as needed. For example, the following non-exhaustive list of customizations might be implemented:
readonly Resource. Note that in this case the Resource's readonly
aspect will likely appear with a value of true even for an admin users.The goal of these customizations is not to allow for implementations to violate the specification, rather it is to allow for real-world requirements to be met while maintaining the interoperability goals of the specification.
Implementations are encouraged to contact the xRegistry community if it is unclear if certain customizations would violate the specification.
Implementations MAY (but are NOT REQUIRED) to validate cross-entity
constraints that might be violated due to changes in a referenced entity.
For example, Endpoint's envelope attribute
mandates that all Messages in that Endpoint use that same envelope value.
One of those Messages might have a basemessage value that points to a
Message that breaks that rule. For a variety of reasons (e.g. authorization
constraints), server implementations might not be able to verify this
constraint. Likewise, the same situation might occur via the use of xref.
Clients need to be aware of these possibilities.
Unless otherwise noted, all attributes and extensions MUST be mutable and MUST be one of the following data types:
any - an attribute of this type is one whose type is not known in advance
and MUST be one of the concrete types listed here.array - an ordered list of values that are all of the same data type - one
of the types listed here.
null value to
appear in an array (e.g. [ null, 2, 3 ] in an array of integers). In
these cases, while it is valid for the serialization being used, it is
not valid for xRegistry since null is not a valid integer. Meaning,
the serialization of an array that is syntactically valid for the
format being used, but not semantically valid per the
xRegistry model definition, MUST NOT be
accepted and MUST generate an error
(invalid_attribute).boolean - case-sensitive true or false.decimal - number (integer or floating point).integer - signed integer.map - set of key/value pairs, where the key MUST be of type string. The
value MUST be of one of the types defined here.
[a-z0-9]), :, -, _ or a ..object - a nested entity made up of a set of attributes of these data
types.string - sequence of Unicode characters.timestamp - an RFC3339 timestamp.
Use of a time-zone notation is RECOMMENDED. All timestamps returned by
a server MUST be normalized to UTC to allow for easy (and consistent)
comparisons.uinteger - unsigned integer.uri - an absolute URI ( uriabsolute) or relative URI (urirelative).uriabsolute - absolute URI as defined in RFC 3986 Section
4.3.urirelative - relative URI as defined in RFC 3986 Section
4.2.uritemplate - URI Template as defined in
RFC 6570 Section 3.2.1.url - an absolute URL (urlabsolute) or relative URL (urlrelative).urlabsolute - an absolute URI as defined in RFC 3986 Section
4.3 with the
added "URL" constraints mentioned in RFC 3986 Section
1.1.3.urlrelative - a relative URI as defined in RFC 3986 Section
4.2 with the
added "URL" constraints mentioned in RFC 3986 Section
1.1.3.xid - MUST be a URL (xid) reference to another entity defined within
the Registry. The actual entity attribute value MAY reference a non-existing
entity (i.e. be a dangling pointer), but the syntax MUST reference a
defined/valid type in the Registry. This type of attribute is used in
place of url so that the Registry can do "type checking" to ensure the
value references the correct type of Registry entity. See the definition of
the target model attribute for more
information. Its value MUST start with a /.xidtype - MUST be a URL reference to an
xRegistry model type. The reference MUST point
to one of: the Registry itself (/), a Group type (/<GROUPS>), a
Resource type (/<GROUPS>/<RESOURCES>) or Version type for a Resource
(/<GROUPS>/<RESOURCES>/versions). Its value MUST reference a
defined/valid type in the Registry. It MUST use the plural names of the
referenced types, if it is a Group, Resource or Version.The 6 variants of URI/URL are provided to allow for strict type adherence
when needed. However, for attributes that are simply "pointers" that might
in practice be any of those 6 types, it is RECOMMENDED that uri be used.
Attributes that are defined to be relative URIs or URLs MUST state what they are relative to and any constraints on their values, if any. How, or where, this is specified is out of scope of this specification.
The "scalar" data types are:
booleandecimalintegerstring,timestampuintegeruriuriabsoluteurirelativeuritemplate,urlurlabsoluteurlrelativexidxidtypeNote that any is not a "scalar" type as its runtime value could be a complex
type such as object.
All attributes (specification-defined and extensions) MUST adhere to the following rules:
[a-z0-9_]) and MUST NOT start with a digit ([0-9]).documentation can be considered such an attribute
for description.any
type) but a concrete type is needed to successfully process it, then the
server SHOULD default it to type string. For example, if an extension is
defined as a map whose values are of type any, but it appears in an HTTP
header with a value of 5 (and it is not clear if this would be an integer
or a string), if the server needs to convert this to a concrete data type,
then string is the default choice.any type has been used higher-up in the model. As a result, any portion of
the entity that appears under the scope of an any typed attribute or
map-value is NOT REQUIRED to be validated except to ensure that the syntax
is valid per the rules of the serialization format used.null or not being present
at all, and for the sake of brevity, SHOULD NOT be serialized as part of its
owning entity in server responses. Likewise, specifying them with a value of
null in client requests SHOULD be reserved for cases where the client
needs to indicate a request to delete that attribute value rather than to
leave the attribute untouched (absent in the request), such as when PATCH
is used in the HTTP Binding Protocol.modifiedat and epoch. In other words, as these read-only attributes
are changed, the entity MUST NOT be considered "updated".Implementations of this specification MAY define additional (extension) attributes. However, they MUST adhere to the following rules:
* (undefined) extension attribute
name at that level in the model.any type for one of its parent
attribute definitions.<RESOURCE>* and <COLLECTION>* attributes
that are implicitly defined. Note that if a Resource type has the
hasdocument aspect
set the false then this rule does not apply for
the <RESOURCE>* attributes as those attributes are not implicitly defined
for that Resource type.Use of an attribute (specification defined, or extension) that does not conform to this specification MUST generate an error (invalid_attribute).
The following attributes are used by one or more entities defined by this specification. They are defined here once rather than repeating them throughout the specification.
For easy reference, the JSON serialization of these attributes adheres to this form:
"<SINGULAR>id": "<STRING>""self": "<URL>""shortself": "<URL>""xid": "<XID>""epoch": <UINTEGER>"name": "<STRING>""description": "<STRING>""documentation": "<URL>""icon": "<URL>""labels": { "<STRING>": "<STRING>" * }"createdat": "<TIMESTAMP>""modifiedat": "<TIMESTAMP>""deprecated": "<OBJECT>"The definition of each attribute is defined below:
<SINGULAR>id (id) Attribute 🔗Type: String
Description: An immutable unique identifier of the owning entity.
The actual name of this attribute will vary based on the entity it
identifies. For example, a schema Resource would use an attribute name
of schemaid. This attribute MUST be named registryid for the Registry
itself, and MUST be named versionid for all Version entities.
Constraints:
unreserved
characters
(ALPHA / DIGIT / - / . / _ / ~), : or @, MUST start with
ALPHA, DIGIT or _ and MUST be between 1 and 128 characters in length.
Otherwise, an error (malformed_id) MUST be generated.<SINGULAR>id MUST be treated as "not found".<SINGULAR>id is specified outside of the
serialization of the entity (e.g. part of a request URL, or a map key),
its presence within the serialization of the entity is OPTIONAL. However,
if present, it MUST be the same as any other specification of the
<SINGULAR>id outside of the entity, and it MUST be the same as the
entity's existing <SINGULAR>id if one exists, otherwise an error
(mismatched_id) MUST be generated.Examples:
a183e0a9-abf8-4763-99bc-e6b7fcc9544bmyEntitymyEntity.example.comWhile <SINGULAR>id can be something like a UUID, when possible, it is
RECOMMENDED that it be human friendly as these values will often appear in
user-facing situations such as URLs or as command-line parameters.
Additionally, In cases where name is absent, the
<SINGULAR>id might be used as the display name.
Note, since <SINGULAR>id is immutable, in order to change its value, a new
entity would need to be created with the new <SINGULAR>id that is a deep-copy
of the existing entity. Then the existing entity would be deleted.
self Attribute 🔗Type: URL
Description: A server-generated unique URL referencing the current entity.
Each entity in the Registry MUST have a unique self URL value that
locates the entity in the Registry hierarchy and from where the entity can
be retrieved.
When specified as an absolute URL, it MUST be based on the URL of the
Registry root appended with the hierarchy path of the Registry
entities/collections leading to the entity (its xid value).
In the case of pointing to an entity that has a <SINGULAR>id attribute,
the URL MUST be a combination of the URL used to retrieve its parent
appended with its <SINGULAR>id value.
API View Constraints:
hasdocument aspect
is set to true, then (based on the protocol binding being used) this
attribute might need to include some indicator that the xRegistry metadata
is to be returned rather than the domain-specific document. See the
Registry Entity section for how this might
manifest itself for HTTP.Document View Constraints:
#JSON-POINTER where the JSON-POINTER
locates this entity within the current document. See Doc Flag
for more information.$details in the
HTTP binding case).Examples:
https://example.com/registry/schemagroups/g1/schemas/s1$details (API View)https://example.com/registry/endpoints/ep1 (API View)#/endpoints/ep1 (Document View)shortself Attribute 🔗Type: URL
Description: A server-generated unique absolute URL for an entity. This
attribute MUST be an alternative URL for the owning entity's self
(non-$details suffixed) URL. When a client constructs a request based on
the shortself URL, it MAY append $details, or any flags (e.g. query
parameters), that are valid for use on the self URL.
The intention is that shortself SHOULD be shorter in length
than self such that it MAY be used when the length of the URL referencing
the owning entity is important. For example, in cases where the size of a
message referencing this entity needs to be as small as possible.
This specification makes no statement as to how this URL is constructed,
to which host/path it references, or whether a request to this URL
will directly perform the desired operation or whether it returns a
redirect to the full self URL requiring the client to resend the request.
If an entity is deleted and then a new entity is created that results in
the same self URL, this specification does not mandate that the same
shortself be generated, but it MAY do so.
This attribute MUST only appear in the serialization if the shortself
capability is enabled. However, if this capability is enabled, then disabled,
and then re-enabled, the shortself values MUST retain their original
values. In this sense, implementations might create a shortself that is
known for the lifetime of the entity and the capability controls whether
the attribute is serialized or not.
Constraints:
shortself capability is enabled.shortself capability is disabled.self
URL, either directly or indirectly via a protocol-specific redirect.$ character as that is reserved for specification
defined suffixes (such as $details).Examples:
https://tinyurl.com/xreg123 redirects to
https://example.com/endpoints/e1xid Attribute 🔗Type: XID
Description: An immutable server-generated unique identifier of the entity.
Unlike <SINGULAR>id, which is unique within the scope of its parent, xid
MUST be unique across the entire Registry, and as such is defined to be a
relative URL from the root of the Registry. This value MUST be the same as
the <PATH> portion of its self URL, after the Registry's base URL,
without any protocol-specific xRegistry suffix (e.g. $details in the HTTP
case). Unlike some other relative URIs, xid values MUST NOT be shortened
based on the incoming request's URL; xids are always relative to the root
path of the Registry.
This attribute is provided as a convenience for users who need a reference
to the entity without running the risk of incorrectly extracting it from
the self URL, which might be ambiguous at times. The xid value is also
meant to be used as an xref value (see Cross Referencing
Resources, or as the value for attributes of
type xid (see target model
attribute).
Constraints:
/[<GROUPS>/<GID>[/<RESOURCES>/<RID>[/meta | /versions/<VID>]]] and
reference valid Group and Resource types. Otherwise, an error
(malformed_xid) MUST be generated./ character.Examples:
/endpoints/ep1epoch Attribute 🔗Type: Unsigned Integer
Description: A numeric value used to determine whether an entity has been
modified. Each time the associated entity is updated, this value MUST be
set to a new value that is greater than the current one. This attribute
MUST be updated for every update operation, even if no attributes were
explicitly updated, such as a "patch" type of operation when no attributes
are specified. This then acts like a touch type of operation.
During a single write operation, whether this value is incremented for each modified attribute of the entity, or updated just once for the entire operation is an implementation choice.
During a create operation, if this attribute is present in the request, then it MUST be silently ignored by the server.
During an update, or delete, operation, if this attribute is present in the
request, then an error
(mismatched_epoch) MUST be generated if the
request includes a non-null value that differs from the existing value.
This allows for the detection of concurrent, but conflicting, updates to the
same entity to be detected. A value of null MUST be treated the same as a
request with no epoch attribute at all, in which case a check MUST NOT
be performed.
If an entity has a nested xRegistry collection, its epoch value MUST
be updated each time an entity in that collection is added or removed.
However, its epoch value MUST NOT be updated solely due to modifications of
an existing entity in the collection.
Note that Resource entities have an epoch value that is serialized
as part of its meta entity. Its value is only incremented
when the meta attributes are updated, or when a Version is added, or
removed, from that Resource.
Constraints:
Examples:
0, 1, 2, 3name Attribute 🔗Type: String
Description: A human-readable name of the entity. This is often used
as the "display name" for an entity rather than the <SINGULAR>id especially
when the <SINGULAR>id might be something that isn't human friendly, like a
UUID. In cases where name is absent, the <SINGULAR>id value SHOULD be
displayed in its place.
This specification places no uniqueness constraints on this attribute.
This means that two sibling entities MAY have the same value. Therefore,
this value MUST NOT be used for unique identification purposes, the
<SINGULAR>id MUST be used instead.
Note that implementations MAY choose to enforce additional constraints on
this value. For example, they could mandate that <SINGULAR>id and name be
the same value. Or, it could mandate that name be unique within the scope
of a parent entity. How any such requirement is shared with all parties is
out of scope of this specification.
Constraints:
Examples:
My Cool Endpointdescription Attribute 🔗Type: String
Description: A human-readable summary of the purpose of the entity.
Constraints:
Examples:
A queue of the sensor-generated messagesdocumentation Attribute 🔗Type: URL
Description: A URL to additional information about this entity. This specification does not place any constraints on the data returned from a query to this URL.
Constraints:
Examples:
https://example.com/docs/myQueueicon Attribute 🔗Type: URL
Description: A URL to a graphical icon for the owning entity.
Constraints:
Examples:
https://example.com/myRegistry.svglabels Attribute 🔗Type: Map of name/value string pairs
Description: A mechanism in which additional metadata about the entity can be stored without changing the model definition of the entity.
Constraints:
Examples:
"labels": { "owner": "John", "verified": "" }createdat Attribute 🔗Type: Timestamp
Description: The date/time of when the entity was created.
Constraints:
modifiedat value or the current
date/time. Implementations MAY choose to restrict its values if necessary.null MUST use the current date/time
as the new value.createdat or modifiedat attributes set to the current date/time MUST
use the same value in all cases.Examples:
2030-12-19T06:00:00Zmodifiedat Attribute 🔗Type: Timestamp
Description: The date/time of when the entity was last updated.
Constraints:
createdat value or the current
date/time. Implementations MAY choose to restrict its values if necessary.touch type of operation.modifiedat value. However, adding or
removing an entity from a nested xRegistry collection MUST update the
modifiedat value of the parent entity.null or the same as the existing value, then
the current date/time MUST be used as its new value.createdat or modifiedat attributes set to the current date/time MUST
use the same value in all cases.Examples:
2030-12-19T06:00:00Zdeprecated Attribute 🔗Type: Object containing the following properties:
effective
An OPTIONAL property indicating the time when the entity entered, or will
enter, a deprecated state. The date MAY be in the past or future. If this
property is not present the entity is already in a deprecated state.
If present, this MUST be an RFC3339 timestamp.
removal
An OPTIONAL property indicating the time when the entity MAY be removed.
The entity MUST NOT be removed before this time. If this property is not
present, the client cannot make any assumptions as to when the entity
might be removed. Note: as with most properties, this property is mutable.
If present, this MUST be an RFC3339 timestamp and MUST NOT be
sooner than the effective time if present.
alternative
An OPTIONAL property specifying the URL to an alternative entity the
client can consider as a replacement for this entity. There is no
guarantee that the referenced entity is an exact replacement, rather the
client is expected to investigate the entity to determine if it is
appropriate.
documentation
An OPTIONAL property specifying the URL to additional information about
the deprecation of the entity. This specification does not mandate any
particular format or information, however some possibilities include:
reasons for the deprecation or additional information about likely
alternative entities. The URL MUST support retrieval of the information
via a query.
Note that an implementation is not mandated to use this attribute in advance of removing an entity, but is it RECOMMENDED that they do so.
This attribute can appear on Groups and Resources, however, this specification makes no statement as to the relationship, or validity, of the values of each with respect to how they might impact each other.
Constraints:
Examples:
"deprecated": {}"deprecated": {
"removal": "2030-12-19T00:00:00Z",
"alternative": "https://example.com/entities-v2/myentity"
}
constraints Attribute 🔗Type: Map of Resource attributes to be constrained just for this Group.
This attribute is used to create a set of Group instance specific constraints on the Resources that exist within it. For example, with this mechanism a Group can restrict all Resources within it to only have a subset of the allowed values for a particular attribute. This allows for Group instance specific restrictions without requiring the creating of new Resource types.
These restrictions are designed to only allow subsetting of the definitions
specified by the Resource type model and any Group type model
constraints defined. They MUST NOT be
used to extend the allowable values of the attributes being constrained.
The definition of this map is the same as the Group type
constraints attribute.
Any map key value specified here that is the same as a key value included
in the Group type model's constraints,
is interpreted as a request to further constrain the Resource attribute
being referenced.
The two layers of definitions of the constraints are merged such that any
individual constraint aspect defined at the Group instance level MUST
override any constraint aspect mentioned at the Group type level. Absence
of (or null value for) an aspect at the Group instance level MUST NOT
impact any constraints defined at the Group type level.
The following further clarifies this merging:
enum is specified at both levels, then the Group instance enum set
MUST be a subset of the enum defined at the Group type level.equals aspect is defined in both levels then they MUST be the
exact same value. And in that situation, specifying it at the Group
instance level is redundant. For clarity, a Group instance MAY introduce
an equals aspect for a constraint key defined at the Group type level
that has no equals aspect.Constraints:
Examples:
"constraints": {
"schemas.format" : {
"default": "jsonschema/draft-07",
"enum": [ "avro/1.9", "jsonschema/draft-07" ],
"equals": "format"
}
}
The above example mandates that:
format values that
is either avro/1.9 or jsonschema/draft-07. And when not specified,
it will default to jsonschema/draft-07.format attribute is the same as
the owning Group's format values (if present).Registry collections (<GROUPS>, <RESOURCES> and versions) that are
defined by the Registry Model MUST be serialized
according to the rules defined in this section.
The serialization of a collection is done as 3 attributes and they MUST adhere to their respective forms as follows:
"<COLLECTION>url": "<URL>",
"<COLLECTION>count": <UINTEGER>,
"<COLLECTION>": {
# Map of entities in the collection, key is the "<SINGULAR>id" of the entity
}
Where:
<COLLECTION> MUST be the plural name of the collection
(e.g. endpoints, versions).<COLLECTION>url attribute MUST be a URL that can be used to retrieve
the <COLLECTION> map via a protocol-specific query mechanism. This URL
MAY including any necessary filtering and MUST be a
read-only attribute that MUST be silently ignored by a server during a write
operation. This attribute MUST be an absolute URL except in document view
and the collection is inlined, in which case it MUST be a relative URL.<COLLECTION>count attribute MUST contain the number of entities in the
<COLLECTION> map (after any necessary filtering) and MUST
be a read-only attribute that MUST be silently ignored by a server during
a write operation.<COLLECTION> attribute is a map and MUST contain the entities of the
collection (after any necessary filtering), and MUST use
the <SINGULAR>id of each entity as its map key.<COLLECTION>* attribute is REQUIRED or
OPTIONAL will be based on whether the document- or API-view is used. See
the next section for more information.When the <COLLECTION> attribute is expected to be present in the
serialization, but the number of entities in the collection is zero, it MUST
still be included as an empty map (e.g. {}).
The set of entities that are part of the <COLLECTION> attribute is a
point-in-time view of the Registry. There is no guarantee that a future query
to the <COLLECTION>url will return the exact same collection since the
contents of the Registry might have changed. This specification makes no
statement as to whether a subsequent query that is missing previously returned
entities is an indication of those entities being deleted or not.
Examples:
Sample schemagroups collection attributes, with schemagroups inlined.
"schemagroupsurl": "http://registry.example.com/schemagroups",
"schemagroupscount": 9
"schemagroups": {
"Contoso.ERP": {...},
"Fabrikam.InkJetPrinter": {...},
"Fabrikam.Lumen": {...},
"Fabrikam.RoboVac": {...},
"Fabrikam.SmartOven": {...},
"Fabrikam.Watchkam": {...},
"WaterBoiler": {...},
"WindGenerator": {...}
},
The requirements on the presence of the 3 <COLLECTION>* attributes varies
between document and API views, and is defined below:
In document view:
<COLLECTION>url and <COLLECTION>count are OPTIONAL.<COLLECTION> is conditional in responses based on the values in the
Inline Flag. If a collection is part of the flag's value then
<COLLECTION> MUST be present in the response even if it is empty
(e.g. {}). If the collection is not part of the flag value then
<COLLECTION> MUST NOT be included in the response.In API view:
<COLLECTION>url is REQUIRED for responses even if there are no entities
in the collection.<COLLECTION>count is STRONGLY RECOMMENDED for responses even if
there are no entities in the collection. This requirement is not mandated
to allow for cases where calculating the exact count is too costly.<COLLECTION>url and <COLLECTION>count are OPTIONAL in requests and MUST
be silently ignored by the server if present.<COLLECTION> is conditional in responses based on the values in the
Inline Flag. If a collection is part of the flag's value then
<COLLECTION> MUST be present in the response even if it is empty
(e.g. {}). If the collection is not part of the flag value then
<COLLECTION> MUST NOT be included in the response.<COLLECTION> is OPTIONAL for requests. See Updating Nested Registry
Collections for more details.When updating an entity that can contain xRegistry collections, the request
MAY contain the 3 collection attributes. The <COLLECTION>url and
<COLLECTION>count attributes MUST be silently ignored by the server.
If the <COLLECTION> attribute is present, the server MUST process each entity
in the collection map as a request to create or update that entity according to
the semantics of the operation method used. An entry in the map that isn't a
valid entity (e.g. is null) MUST generate an error
(bad_request).
For example, in the case of HTTP:
PUT https://example.com/endpoints/ep1
{
"endpointid": "ep1",
"name": "A cool endpoint",
"messages": {
"mymsg1": { ... },
"mymsg2:" { ... }
}
}
will not only create/update an endpoint Group with an endpointid of ep1
but will also create/update its message Resources (mymsg1 and mymsg2).
Any error while processing a nested collection entity MUST result in the entire request being rejected.
An absent <COLLECTION> attribute, or empty map, MUST be interpreted as a
request to not modify the collection at all.
If a client wishes to delete an entity from the collection, or replace the entire collection, the client MUST use a "delete" type of operations on the collection. This means that delete operations on these entities would need to be handled in dedicated operations, separate from update operations.
In cases where a Resource update operation includes attributes meant to be
applied to the "default" Version of a Resource, and the incoming inlined
versions collections includes that "default" Version, the Resource's default
Version attributes MUST be silently ignored. This is to avoid any possible
conflicting data between the two sets of data for that Version. In other
words, the Version attributes in the incoming versions collection wins.
See Resource Processing Algorithm for more
details.
To better understand this scenario, consider the following HTTP request to
update a Message where the defaultversionid is v1:
PUT http://example.com/endpoints/ep1/messages/msg1
{
"messageid": "msg1",
"versionid": "v1",
"name": "Blob Created"
"versions": {
"v1": {
"messageid": "msg1",
"versionid": "v1",
"name": "Blob Created Message Definition"
}
}
}
If the versions collection were not present with the v1 entity then the
top-level attributes would be used to update the default Version (v1 in this
case). However, because it is present, the request to update v1 becomes
ambiguous because it is not clear if the server is meant to use the top-level
attributes or if it is to use the attributes under the v1 entity of the
versions collection. When both sets of attributes are the same, then it does
not matter. However, in this example, the name attributes have different
values. The paragraph above mandates that in these potentially ambiguous cases
the entity in the versions collection is to be used and the top-level
attributes are to be ignored. So, in this case the name of the default (v1)
Version will be Blob Created Message Definition.
The Registry entity represents the root of a Registry and is the main entry-point for traversal and discovery.
The serialization of the Registry entity MUST adhere to this form:
{
"specversion": "<STRING>",
"registryid": "<STRING>",
"self": "<URL>",
"shortself": "<URL>", ?
"xid": "<XID>",
"epoch": <UINTEGER>,
"name": "<STRING>", ?
"description": "<STRING>", ?
"documentation": "<URL>", ?
"icon": "<URL>", ?
"labels": { "<STRING>": "<STRING>" * }, ?
"createdat": "<TIMESTAMP>",
"modifiedat": "<TIMESTAMP>",
"capabilities": { Registry capabilities }, ? # Only if inlined
"model": { Registry model }, ? # Only if inlined
"modelsource": { Registry model }, ? # Only if inlined
# Repeat for each Group type
"<GROUPS>url": "<URL>", # e.g. "endpointsurl"
"<GROUPS>count": <UINTEGER>, # e.g. "endpointscount"
"<GROUPS>": { Groups collection } ? # Only if inlined
}
The Registry entity includes the following common attributes:
registryid - REQUIRED in API and document
views. OPTIONAL in requests.self - REQUIRED in API and document views.
OPTIONAL/ignored in requests.shortself - OPTIONAL in API and document views,
based on the shortself capability. OPTIONAL/ignored in requests.xid - REQUIRED in API and document views.
OPTIONAL/ignored in requests.epoch - REQUIRED in API and document views. OPTIONAL
in requests.name - OPTIONAL.description - OPTIONAL.documentation - OPTIONAL.icon - OPTIONAL.labels - OPTIONAL.createdat - REQUIRED in API and document views.
OPTIONAL in requests.modifiedat - REQUIRED in API and document views.
OPTIONAL in requests.and the following Registry-level attributes:
specversion Attribute 🔗Type: String.
Description: The version of this specification that the document adheres to.
Constraints:
Examples:
1.0capabilities Attribute 🔗Type: Registry Capabilities
Description: The set of capabilities (features) supported by the Registry. See Registry Capabilities for more information.
During a write operation:
null for this attribute MUST result in resetting the
capabilities to the server's default values.modelsource, the state of those
particular settings prior to the request MUST be used for the duration
of the current request. For example:
ignore=capabilities would be controlled by
the pre-request configuration since, if set, would result in ignoring
any capabilities attribute in the request.formats would be controlled by the
updated capabilities to ensure proper validation of the Registry data
prior to completing the request.Constraints:
model Attribute 🔗Type: Registry Model.
Description: A full description of the Groups, Resources and attributes (specification-defined and extensions) as defined by the current model associated with this Registry. See Registry Model.
This view of the model is useful for tooling that needs a complete view of what will be part of any message exchange with the server.
Note that any "include" directives that were included in the model definition MUST NOT be present in this view of the model.
Constraints:
modelsource Attribute 🔗Type: Registry Model.
Description: The "model" definition that was last used to define this
Registry's model. Unlike model, which includes all aspects of the model,
this is meant to represent just the customizations, or extensions, to the
base xRegistry model as defined this
specification. This allows for users to view (and edit) just the custom
aspects of the model without the "noise" of the specification-defined parts.
During a write operation:
null, or an empty JSON object ({}), MUST result
in all Groups, Resources and extension Registry-level attributes being
removed from the model.capabilities attribute is also present,
then capabilities MUST be processed before modelsource.The serialization of this attribute MUST be semantically equivalent to what was used to create the model, but it is NOT REQUIRED to be syntactically equivalent. In other words, it might be "pretty-printed", but it MUST NOT include additional aspects even if those are defined/mandated by the specification or server implementation.
Constraints:
<GROUPS> Collections 🔗Type: Set of Registry Collections
Description: A list of Registry collections that contain the set of Groups supported by the Registry.
Constraints:
In order to programmatically discover which capabilities are supported by an implementation, servers SHOULD support exposing this information via a "capabilities" map that lists each supported feature along with any related configuration detail that will help in successful usage of that feature.
The "key" of the capabilities-map is the "name" of each feature, and the
"value" is a feature-specific set of configuration values, with the most basic
being a <BOOLEAN> value of true to indicate support for the feature.
The JSON serialization of capabilities map MUST be of the form:
{
"available": { "<STRING>": { "mutable": <BOOLEAN> } + },
"compatibilities": { "<STRING>": [ "<STRING>" * ] * }, ?
"flags": [ "<STRING>" * ], ?
"formats": [ "<STRING>" * ], ?
"ignores": [ "<STRING>" * ], ?
"mutable": [ "<STRING>" * ], ?
"pagination": <BOOLEAN>, ?
"shortself": <BOOLEAN>, ?
"specversions": [ "<STRING>" ], ?
"versionmodes": [ "<STRING>" ], ?
"<STRING>": ... capability configuration ... * // Extension capabilities
}
Where:
"<STRING>", as a key, MUST be the name of the capability. This
specification places no restriction on the "<STRING>" value, other than it
MUST be unique across all capabilities and not be an empty string. It is
RECOMMENDED that extensions use some domain-specific name to avoid possible
conflicts with other extensions.All capability values, including extensions, MUST be defined as one of the following:
When serializing their supported capabilities, servers MUST include all capabilities (including extensions) since the absence of a capability indicates lack of support for that feature. However, absence, presence, or configuration values of a feature in the map MAY vary based on the authorization level of the client making the request.
The list of values for the arrays MUST be case-insensitive and MAY include extension values.
For clarity, servers MUST include all supported capabilities in the serialization, even if they are set to their default values or have empty lists.
It is RECOMMENDED that protocols for this specification support retrieval of
the capabilities via the inlining of the Registry entity's capabilities
attribute well as a stand-alone map independent of the Registry entity (e.g.
GET /capabilities in the HTTP case). However,
as with all interactions with a server, security/access controls MAY be
needed.
The following defines the specification-defined capabilities:
available Capability 🔗Name: available
Type: Map of types of xRegistry metadata available.
Description: The list of the various types of metadata available from this xRegistry instance. This information is meant to be used by clients, and tooling, to programmatically discover which pieces of xRegistry information are available to query or edit.
The "key" of each map entry MUST be one of the defined values listed below.
The "value" of each map entry MUST be an Object with a nested "mutable"
boolean attribute indicating whether or not the corresponding data is
user-editable.
Some of the items listed are available via more than one mechanism. For
example, "model", in the HTTP protocol case, is available the /model API
as well as via the ?inline=model query parameter. In these cases, the data
MUST be available via all supported retrieval mechanisms. For example, it
would violate this specification if the /model API was supported but
?inline=model was not, assuming the ?inline flag was supported. If the
?inline flag, in general, was not supported then only allowing the
retrieval of the model via the /model API is permitted. Note that if
a separate API is defined for a piece of data, it MUST be supported if that
data type is listed in this capability.
Metadata not listed in this capability is to be assumed to be unavailable via all mechanisms. Attempts to access unavailable metadata MUST generate an error (not_available).
Defined values:
capabilitiescapabilitiesofferedentities (xRegistry root entity, Groups, Resource and Versions. MUST
have a mutable value of false)exportmodel (MUST have a mutable value of false)modelsourceWhen not specified, the default value MUST be just the entities value,
with a "mutable" value of true.
This capability MUST always include entities as a value, even if its
mutable attribute is false.
Implementations MAY define additional values.
Implementations MAY define additional attributes for the nested Object.
It is STRONGLY RECOMMENDED that implementations also support at least
capabilities and model.
Examples:
"available": {
"capabilities": { "mutable": false },
"capabilitiesoffered": { "mutable": false },
"entities": { "mutable": true },
"export": { "mutable": false },
"model": { "mutable": false },
"modelsource": { "mutable": true }
}
compatibilities Capability 🔗Name: compatibilities
Type: Map of compatibility rules per format
Description: The set of compatibility rules that are available for each
supported format. Each map key MUST be a case-insensitive Capabilities
formats value, and the map value MUST be the list of case-insensitive
compatibility rules supported by that format. The key MAY include a
* (wildcard) character that matches zero or more instances of any
character at that location in the string. Similar to a .* in regular
expressions.
An error
(capability_error) MUST be generated if a specified
key/format isn't in Capabilities formats list or the compatibility rule
specified is not supported for that format (i.e. that combination of
format/compatibility is not listed in the compatibilities offered
capabilities).
Compatibility rules are semantic requirements that define how Versions of a
Resource are allowed to change over time. For example, the compatibility rule
of backward typically means that a newer Version of the Resource is
backwards compatible with the next oldest Version of that Resource. What
"backward compatible" means will vary based on what the Resource/Version
represents. The Version's format attribute is meant to be the indicator
as to "what" the Version is - which is why it is the "key" into this
compatibilities map.
When not specified, the default value MUST be an empty map and no support for Version compatibility is supported.
Examples:
"compatibilities": { "avro": [ "backward", "forward" ] }"compatibilities": { "jsonschema*": [ "backward", "forward", "full" ] }flags Capability 🔗flagsbinary, collections, doc, epoch, filter, ignore, inline,
setdefaultversionid, sort, specversion."flags": [ "filter", "inline" ] # Just these 2"flags": [ "*" ] # All supported flags (requests only)formats Capability 🔗formatsformat values that can be validated. An error
(capability_error) MUST be generated for any value
specified is not supported by the server (i.e. not listed in the formats
offered capabilities)."formats": [ "avro", "protobuf"", "jsonSchema" ]ignores Capability 🔗ignorescapabilities, defaultversionid, defaultversionsticky, id, epoch,
modelsource, readonly."ignores": [ "epoch", "id" ] # Just these 2"ignores": [ "*" ] # All supported values (requests only)pagination Capability 🔗paginationfalse.shortself Capability 🔗shortselfshortself attribute MUST be included
in the server serialization of the entities within the Registry (value of
true).false.specversions Capability 🔗specversionsspecversion flag.1.0-rc3Implementations MAY support clients updating the capabilities of the server.
If so, they SHOULD support it via updates to the Registry entity's
capabilities attribute as well as updates via a stand-alone map independent
of the the Registry entity (e.g.
PUT /capabilities in the HTTP case).
The request to update the capabilities SHOULD include a serialization of the capability map as described above. Whether it includes the full set of supported capabilities or a subset will vary based on the protocol defined. However, the following rules apply in both cases.
For any capability that is an array of strings, a value of "*" MAY be used to
indicate that the server MUST replace "*" with the full set of items that
are available. An error (capability_wildcard) MUST be
generated if "*" appears along with any other value in the list. "*"
MUST NOT appear in the serialization in any server's response.
Regardless of the mechanism used to update the capabilities, the Registry's
epoch value MUST be incremented upon each update.
The enum of values allows for some special cases:
* as a wildcard character in a value
to indicate zero or more unspecified characters MAY appear at that location
in the value string.A request to update a capability with a value that is compliant with the
format of the capabilities definition MAY still generate an error
(capability_error) if the server determines it cannot
support the request. For example, due to authorization concerns or the value,
while syntactically valid, isn't allowed in certain situations.
A request to update a capability that doesn't include a mandatory value (such
as the current specification version for specversions), MUST generate an
error (capability_missing_value).
A request to update a capability with an invalid value MUST generate an error (capability_value).
A request to update an unknown capability MUST generate an error (capability_unknown).
Normally modifying the capabilities of a server and modifying any entity data are typically two very distinct actions, and will not normally happen at the same time. However, if the situation does occur, a consistent (interoperable) processing order needs to be defined.
In order for an authorized client to update the capabilities of a server it might need to first discover the list of available values for each capability. This information is described via a map (similar to the capability map itself) where each supported capability's name is the key of the map, and the corresponding value provides details about the capability (e.g. allowed values and pointer to its documentation).
The JSON serialization of the capabilities offering map MUST be of the form:
{
"<STRING>": { # Name of Capability attribute
"type": "<TYPE>",
"enum": [ <VALUE> * ], ? # Allowed values for scalars
"min": <VALUE>, ?
"max": <VALUE>, ?
"documentation": "<URL>", ?
"attributes": { ... }, ? # If "type" is object
"item": { # If "type" is map,array
"type": "<TYPE>", # Value type of map, array type
"attributes": { ... }, ? # If this item "type" is object (see above)
"item": { ... } ? # If this item "type" is map,array (see above)
}, ?
} *
}
Where:
"<STRING>" MUST be the capability name.<TYPE> MUST be one of the data types specified in
Attributes and Extensions."enum", when specified, contains a list of zero or more <VALUE>s whose
type MUST match either "type" (when scaler) or "item.type" if "type"
is "array" or "map" and "item.type" is a scalar."min" and "max", when specified, MUST match the same type as either
"type" or "item.type" if "type" is "array". These indicate the
minimum or maximum (inclusive) value range of this capability. When not
specified, there is no stated lower (or upper) limit. These MUST only be
used when "type" is a numeric type."documentation" provides a URL with additional information about the
capability."attributes", when specified, contains the list (as a map) of attributes
defined for the "object"-typed capability. This makes the schema of the
capability recursive."item" MUST be specified when "type" is "array" or "map", and
specify details about the items in the array, or values of the map.
Note, all map keys MUST be of type string.Notice the syntax borrows much of the same structure from the xRegistry model definition language.
To maximize discoverability for clients, even in cases where there is no variability allowed for certain capabilities, they MUST still be listed in a server's "offering" serialization.
For example, if pagination is not supported, but is a known feature, then a
server MUST still include:
"pagination": {
"type": "boolean",
"enum": [ false ]
}
in the serialization of its capabilities offering map.
Examples:
{
"available": {
"type": "object",
"attributes": {
"capabilities": {
"type": "object",
"attributes": { "mutable": { "type": "boolean" } }
},
"capabilitiesoffered": {
"type": "object",
"attributes": { "mutable": { "type": "boolean" } }
},
"entities": {
"type": "object",
"attributes": { "mutable": { "type": "boolean", "enum": [ false ] } }
},
"export": {
"type": "object",
"attributes": { "mutable": { "type": "boolean", "enum": [ false ] } }
},
"model": {
"type": "object",
"attributes": { "mutable": { "type": "boolean" } }
},
"modelsource": {
"type": "object",
"attributes": { "mutable": { "type": "boolean" } }
}
}
},
"compatibilities": {
"type": "object",
"attributes": {
"avro": {
"type": "array",
"item": { "type": "string" },
"enum": [ "backward", "forward" ]
},
"protobuf": {
"type": "array",
"item": { "type": "string" },
"enum": [ "backward" ]
}
}
},
"flags": {
"type": "array",
"item": {
"type": "string"
},
"enum": [ "binary", "collections", "doc", "epoch", "filter", "ignore",
"inline", "setdefaultversionid", "sort", "specversion" ]
},
"formats": {
"type": "array",
"item": {
"type": "string"
},
"enum": [ "avro", "protobuf", "jsonSchema" ]
},
"ignores": {
"type": "array",
"item": {
"type": "string"
},
"enum": [ "capabilities", "defaultversionid", "defaultversionsticky",
"epoch", "id", "modelsource", "readonly" ]
},
"mutable": {
"type": "array",
"enum": [ "capabilities", "entities", "modelsource" ],
"item": {
"type": "string"
}
},
"pagination": {
"type": "boolean",
"enum": [ false, true ]
},
"shortself": {
"type": "boolean",
"enum": [ false, true ]
},
"specversions": {
"type": "array",
"enum": [ "1.0-rc3" ],
"item": {
"type": "string"
}
},
"versionmodes": {
"type": "array",
"enum": [ "manual", "createdat", "modifiedat", "semver" ],
"item": {
"type": "string"
}
}
}
Groups represent entities that typically act as a collection mechanism for related Resources. However, it is worth noting that Groups do not have to have Resources associated with them. It is possible to have Groups be the main (or only) entity of a Registry. Each Group type MAY have any number of Resource types within it. This specification does not define how the Resources within a Group type are related to each other.
The serialization of a Group entity MUST adhere to this form:
{
"<GROUP>id": "<STRING>",
"self": "<URL>",
"shortself": "<URL>", ?
"xid": "<XID>",
"epoch": <UINTEGER>,
"name": "<STRING>", ?
"description": "<STRING>", ?
"documentation": "<URL>", ?
"icon": "<URL>", ?
"labels": { "<STRING>": "<STRING>" * }, ?
"createdat": "<TIMESTAMP>",
"modifiedat": "<TIMESTAMP>",
"deprecated": {
"effective": "<TIMESTAMP>", ?
"removal": "<TIMESTAMP>", ?
"alternative": "<URL>", ?
"documentation": "<URL>"?
}, ?
# Repeat for each Resource type in the Group
"<RESOURCES>url": "<URL>", # e.g. "messagesurl"
"<RESOURCES>count": <UINTEGER>, # e.g. "messagescount"
"<RESOURCES>": { Resources collection } ? # If inlined
}
Group extension attributes would also appear as additional top-level JSON attributes.
Groups include the following common attributes:
<GROUP>id - REQUIRED in API and document views.
OPTIONAL in requests.self - REQUIRED in API and document views.
OPTIONAL/ignored in requests.shortself - OPTIONAL in API and document views,
based on the shortself capability. OPTIONAL/ignored in requests.xid - REQUIRED in API and document views.
OPTIONAL/ignored in requests.epoch - REQUIRED in API and document views. OPTIONAL in
requests.name - OPTIONAL.description - OPTIONAL.documentation - OPTIONAL.icon - OPTIONAL.labels - OPTIONAL.createdat - REQUIRED in API and document views.
OPTIONAL in requests.modifiedat - REQUIRED in API and document views.
OPTIONAL in requests.deprecated - OPTIONAL.and the following Group-level attributes:
<RESOURCES> Collections 🔗Type: Set of Registry Collections.
Description: A list of Registry collections that contain the set of Resources supported by the Group.
Constraints:
Resources typically represent the main entity that the Registry is managing.
Each Resource is associated with a Group to aid in their discovery and to show
a relationship with Resources in that same Group. Resources appear within the
Group's <RESOURCES> collection.
Resources, like all entities in the Registry, can be modified but Resources
can also have a version history associated with them, allowing for users to
retrieve previous Versions of the Resource. In this respect, Resources have
a 2-layered definition. The first layer is the Resource entity itself,
and the second layer is its versions collection - the version history of
the Resource.
The Resource entity serves three purposes:
It represents the collection of historical Versions of the data being
managed. This is true even if the Resource type is defined to not use
versioning, meaning the number of Versions allowed is just one. The
Versions will appear as nested xRegistry collection under the versions
attribute.
It acts as an alias for the "default" Version of the Resource. This means that any operation (read or write) that deals with attributes exposed via the Resource, but are inherited from the "default" Version, MUST act upon that Version's corresponding attribute. See Default Version of a Resource, Updating Nested Registry Collections and Version Entity for additional semantics that apply to write operations on Resources.
It has a set of attributes for Resource-level metadata - data that is not
specific to one Version of the Resource but instead applies to the
Resource in general. Most of these attributes appear under a
meta entity so as to keep them separate
from any default Version-level attributes that might appear. Note that
these attributes do not appear on the Versions.
When a Resource is serialized as xRegistry metadata without the inherited
default Version attributes, such as when the doc flag is used,
it MUST adhere to the following:
{
"<RESOURCE>id": "<STRING>",
"self": "<URL>", # URL to Resource, not Version
"shortself": "<URL>", ?
"xid": "<XID>", # Relative URI to Resource
"metaurl": "<URL>", # URL to 'meta' entity
"meta": { meta entity }, ? # Only if inlined
"versionsurl": "<URL>", # Absolute URL to versions
"versionscount": <UINTEGER>, # Size of versions collection
"versions": { map of Versions } # Only if inlined
}
When the default Version attributes do appear in the xRegistry metadata
serialization of the Resource (e.g. the doc flag is not used)
it MUST adhere to the following:
{
"<RESOURCE>id": "<STRING>",
"versionid": "<STRING>", # Default Version's ID
"self": "<URL>",
"shortself": "<URL>", ?
"xid": "<XID>",
"epoch": <UINTEGER>, # Start of default Ver attributes
"name": "<STRING>", ?
"isdefault": true,
"description": "<STRING>", ?
"documentation": "<URL>", ?
"icon": "<URL>", ?
"labels": { "<STRING>": "<STRING>" * }, ?
"createdat": "<TIMESTAMP>",
"modifiedat": "<TIMESTAMP>",
"ancestorid": "<STRING>",
"contenttype": "<STRING>", ?
"<RESOURCE>url": "<URL>", ? # If not local
"<RESOURCE>": ... Resource document ..., ? # If local & inlined & JSON
"<RESOURCE>base64": "<STRING>", ? # If local & inlined & ~JSON
# End of default Ver attributes
"metaurl": "<URL>",
"meta": { meta entity }, ? # Only if inlined
"versionsurl": "<URL>",
"versionscount": <UINTEGER>,
"versions": { map of Versions } ? # Only if inlined
}
Note that the Version attributes that conflict with the Resource
attributes (e.g. self, shortself, xid) are not inherited by this
serialization. Their values are for the Resource and not the default
Version's.
The Resource entity includes the following common attributes:
<RESOURCE>id - REQUIRED in API and document
views. OPTIONAL in requests.self - REQUIRED in API and document views.
OPTIONAL/ignored in requests. References the Resource, not the default
Version.shortself - OPTIONAL in API and document views,
based on the shortself capability. OPTIONAL/ignored in requests.
References the Resource, not the default Version.xid - REQUIRED in API and document views.
OPTIONAL/ignored in requests. References the Resource, not the default
Version.and the following Resource-level attributes:
metaurl Attribute 🔗Type: URL
Description: A server-generated URL referencing the Resource's
meta entity.
API View Constraints:
meta entity.Document View Constraints:
meta entity is inlined in the document, then this attribute
MUST be a relative URL of the form #JSON-POINTER where the JSON-POINTER
locates the meta entity within the current document. See
Doc Flag for more information.meta entity is not inlined in the document, then this attribute
MUST be an absolute URL per the API view constraints listed above.Examples:
https://example.com/endpoints/ep1/messages/msg1/meta (API view)#/endpoints/ep1/messages/msg1/meta (Document view)meta Attribute 🔗Type: Object
Description: An object that contains most of the Resource-level attributes.
See Meta Entity for more information.
During a write operation, the absence of the meta attribute indicates that
no changes are to be made to the meta entity.
Constraints:
versions Collection 🔗Type: Registry Collection
Description: The set of xRegistry Collection attributes related to the Versions of the Resource.
Note that Resources MUST have at least one Version.
Constraints:
Unlike Groups, which consist entirely of xRegistry managed metadata, Resource
Versions often have their own domain-specific data and document format that
needs to be kept distinct from the Version metadata. As discussed previously,
the model definition for Resource types has a
hasdocument aspect
indicating whether a Resource type defines its own separate document or not.
This specification does not define any requirements for the contents of this
separate document, and it doesn't even need to be stored within the Registry.
The Version MAY choose to simply store a URL reference to the externally
managed document instead. When the document is stored within the Registry, it
can be managed as an opaque array of bytes and is available via the Version
<RESOURCE> or
<RESOURCE>base64 attributes.
When a Resource is configured to possibly have a separate document, clients can choose whether they want to interact with that document or with the xRegistry metadata. In this sense, there are two "views" of the Resource/Version that client can choose from.
Each xRegistry binding specification will define the mechanism by which clients
can indicate which view of the Resource/Version they want to interacting with.
For HTTP, see the
Resource Metadata vs Resource Document
section for more information, in particular about the use of the $details
URL suffix. Those specifications will also define any protocol-specific
serialization rules when the Resource domain-specific document view is used.
The following rules apply to the processing of write operations for Resources and Versions:
meta.defaultversionid is not set as part of the
request, then use of the
SetDefaultVersionID Flag is RECOMMENDED. See
Default Version of a Resource for more
information.The following sections go into more details about the processing of requests to create/update Resources and Versions.
Processing of a request to create/update a Resource has many different aspects to consider. The following describes the general algorithm that servers are expected to follow. Implementations are not mandated to follow this exact sequence of actions but the net semantic results MUST be adhered to.
Users of Registries will most likely not need to understand all of the details
mentioned in this section. Additionally, users are encouraged to limit
themselves to operations that modify one entity at a time whenever possible to
keep the interactions simple (e.g. operate on single Versions directly rather
than the entire versions collection in one request). Then operations that
need the level of complexity detailed in this section would only be needed for
"import" type of cases.
For this discussion, it is assumed that some variant of the Resource's JSON is present in a write operation request, as shown in the following abbreviated JSON serialization:
{
"<RESOURCE>id": "<STRING>",
"versionid": "<STRING>",
"epoch": <UINTEGER>,
"isdefault": true,
... other default Version attributes ...
"meta": {
"<RESOURCE>id": "<STRING>",
"xref": "<XID>",
"epoch": <UINTEGER>,
"defaultversionid": "<STRING>",
"defaultversionsticky": <BOOLEAN>
... other meta-level attributes ...
},
"versions": { ... map of Versions ... }
}
Notice that the serialization can be broken into 3 distinct parts:
meta sub-object.versions collection of Resource Versions.The overall processing of the request message is as follows:
versions collection, if present.versions collection.ancestorid values as needed,
based on the Resource's
versionmode value.meta sub-object, if present.meta.defaultversionid as needed.matchversions
checks.maxversions
constraints. Note that
this might require updating the ancestorid values
again after some Versions have been deleted.The following provides additional details:
Implementation optimizations:
meta.xref value
might allow for skipping unnecessary work.Step 2 - Processing the Resource's default Version attributes:
versionid attribute is present, and that Version
is not in the request's versions collection, then a new Version with
that versionid MUST be created with the Resource-level attributes. If
it is in the versions collection then the Resource-level attributes
MUST be ignored.versionid is not present, but meta.defaultversionid is present,
and that Version is not in the request's versions collection, then a
new Version with that versionid MUST be created, with the
Resource-level attributes. If it is in the versions collection then
the Resource-level attributes MUST be ignored. Also see
SetDefaultVersionID Flag for an additional
mechanism by which it might be set.versions
collection will dictate the result:
versions is missing, or empty, then the server MUST generate a
new unique versionid value and create a new Version
using that value, with the Resource-level attributes.versions is present with at least one Version, then the
Resource-level attributes MUST be ignored. This is because without
any indication from the client as to which Version the Resource-level
attributes need to be applied to, rather than creating a new Version,
the assumption is that versions contains all of the Versions that are
meant to be created.See Resource Update Samples for examples.
<RESOURCE>* Attribute Processing 🔗The processing of the 3 <RESOURCE>* attributes MUST follow these rules:
<RESOURCE>url has no value,
then absence of all 3 attributes MUST leave all 3 unchanged.null for any of the 3 attributes MUST result in
same net effect as defining the entity's domain-specific document to be
an empty document.<RESOURCE> is present, the server MAY choose to modify non-semantic
significant characters. For example, to remove (or add) whitespace. In
other words, there is no requirement for the server to persist the
document in the exact byte-for-byte format in which it was provided. If
that is desired then clients MUST use <RESOURCE>base64 instead.<RESOURCE> is present,
if no contenttype value is provided then the server MUST set it to same
type as the incoming request, e.g. application/json, even if the entity
previous had a contenttype value.<RESOURCE> or <RESOURCE>base64 is
present, if no contenttype value is provided then the server MUST set it
to the same type as the incoming request, e.g. application/json, only if
the entity does not already have a value. Otherwise, the existing value
remains unchanged.Typically, Resources exist within the scope of a single Group, however there might be situations where a Resource needs to be related to multiple Groups. In these cases, there are two options. First, a copy of the Resource could be made into the second Group. The obvious downside to this is that there's no relationship between the two Resources and any changes to one would need to be done in the other - running the risk of them getting out of sync.
The second, and better, option is to create a cross-reference from one
(the "source" Resource) to the other ("target" Resource). This is done
by setting the meta.xref attribute on the source Resource to be the xid
of the target Resource.
For example: a schema Resource instance defined as:
{
"schemaid": "mySchema",
"meta": {
"xref": "/schemagroups/group2/schemas/sharedSchema"
}
}
means that mySchema references sharedSchema, which exists in group2.
When this source Resource (mySchema) is retrieved, all of the target
Resource's attributes (except its <RESOURCE>id) will appear as if they were
locally defined.
So, if the target Resource (sharedSchema) is defined as:
{
"resourceid": "sharedSchema",
"versionid": "v1",
"self": "http://example.com/schemagroups/group2/schemas/sharedSchema",
"xid": "/schemagroups/group2/schemas/sharedSchema",
"epoch": 2,
"isdefault": true,
"createdat": "2024-01-01-T12:00:00Z",
"modifiedat": "2024-01-01-T12:01:00Z",
"ancestorid": "v1",
"metaurl": "http://example.com/schemagroups/group2/schemas/sharedSchema/meta",
"versionscount": 1,
"versionsurl": "http://example.com/schemagroups/group2/schemas/sharedSchema/versions"
}
then the resulting serialization of the source Resource would be:
{
"resourceid": "mySchema",
"versionid": "v1",
"self": "http://example.com/schemagroups/group1/schemas/mySchema",
"xid": "/schemagroups/group1/schemas/mySchema",
"epoch": 2,
"isdefault": true,
"createdat": "2024-01-01-T12:00:00Z",
"modifiedat": "2024-01-01-T12:01:00Z",
"ancestorid": "v1",
"metaurl": "http://example.com/schemagroups/group1/schemas/mySchema/meta",
"meta": {
"resourceid": "mySchema",
"self": "http://example.com/schemagroups/group1/schemas/mySchema/meta",
"xid": "/schemagroups/group1/schemas/mySchema/meta",
"xref": "/schemagroups/group2/schemas/sharedSchema",
"createdat": "2024-01-01-T12:00:00Z",
"modifiedat": "2024-01-01-T12:01:00Z",
"readonly": false,
"defaultversionid": "v1",
"defaultversionurl": "http://example.com/schemagroups/group1/schemas/mySchema/versions/v1",
"defaultversionsticky": false
},
"versionscount": 1,
"versionsurl": "http://example.com/schemagroups/group1/schemas/mySchema/versions"
}
Note:
meta.xref
attribute. For example, its <RESOURCE>id MUST be the source's id and not
the target's.xref attribute MUST always appear when the source's meta sub-object
is serialized so clients can easily determine that this Resource is a
cross-referenced Resource.xref XID MUST be the xid of the target Resource.From a consumption (read) perspective, aside from the presence of the xref
attribute, the Resource appears to be a normal Resource that exists within
group1. All of the specification-defined features (e.g. inline,
filter request flags) MAY be used when retrieving the Resource.
However, from a write perspective it is quite different. In order to update the target Resource's attributes (or nested entities), a write operation MUST be done on the appropriate target Resource entity directly. Write operations on the source MAY be done, however, the changes are limited to converting it from a "cross-reference" Resource back into a "normal" Resource. See the following for more information:
When converting a "normal" Resource into a cross-reference Resource (adding
an xref value), or creating/updating a Resource that is a cross-reference
Resource, the following MUST be adhered to:
xref attribute with a value that is
the xid of the target Resource.<RESOURCE>id attribute (of the source
Resource) on the Resource or meta entity.epoch within meta (to do an epoch validation
check) only if the Resource already exists.When converting a cross-reference Resource back into a "normal" Resource, the following MUST be adhered to:
xref attribute or set it to null.meta.createdat value
MUST be reset to the timestamp of when this source Resource was originally
created.meta.modifiedat value
MUST be set to "now".meta.epoch value MUST be greater than the original
Resource's previously known value (if any) and greater than the target
Resource's meta.epoch value. In pseudocode this is:
epoch = max(original_Epoch, target_Resource_Epoch) + 1.
This will ensure that the Resource's epoch value will never decrease as a
result of this operation. Note that going from a "normal" Resource to a
cross-reference Resource does not have this guarantee. If the target Resource
no longer exists then target_Resource_Epoch MUST be treated as zero.If the target Resource itself is a cross-reference Resource, then including
the target Resource's attributes MUST NOT be done when serializing the
source Resource. Recursive, or transitively, following of xref XIDs is not
done.
Both the source and target Resources MUST be of the same Resource model type,
simply having similar Resource type definitions is not sufficient. This
implies that the
ximportresources feature to
reference a Resource type from another Group type definition MUST be
used.
An xref value that points to a non-existing Resource, either because
it was deleted, never existed or the current client does not have permission
to see it, is not an error and is not a condition that a server is REQUIRED to
detect. In these "dangling xref" situations, the serialization of the source
Resource will not include any target Resource attributes or nested collections.
Rather, it will only show the <RESOURCE>id and xref attributes. Therefore,
a client that receives a response containing only those two attributes can
treat this as an indicator that the target Resource is inaccessible, and can
make the determination as to whether this is something to investigate or not.
However, a non-existing Resource is not the same as a poorly formed XID
value. An xref that isn't syntactically correct, or references a
non-existing Group or Resource, MUST generate an error
(malformed_xref).
The meta entity (within a Resource) contains most of the Resource-level
attributes that are global to the Resource, and not Version-specific. It is
an entity in its own right, meaning it supports the normal "read" and "write"
operation targeted directly to it.
Each Resource MUST have a Meta entity, and when the Resource is deleted then the Meta entity MUST also be deleted. Delete requests directed to the Meta entity MUST generate an error (action_not_supported).
A non-patch type of write operation that includes a Resource, as a mechanism
to update its meta entity would need to include the Resource's default
Version attributes in the request. If not, the server will interpret it as a
request to delete the default Version attributes, which is probably not the
desired result. Instead, a write operation directly targeted to the meta
entity would be a better choice, or a "patch" type of operation where only
the meta entity is included in the request.
The serialization of the Meta entity MUST adhere to this form:
{
"<RESOURCE>id": "<STRING>", # Resource ID
"self": "<URL>", # URL to this "meta" entity
"shortself": "<URL>", ?
"xid": "<XID>", # Relative URI to this "meta"
"xref": "<XID>", ? # Ptr to linked Resource
"epoch": <UINTEGER>, # Resource's epoch
"labels": { "<STRING>": "<STRING>" * }, ?
"createdat": "<TIMESTAMP>", # Resource's
"modifiedat": "<TIMESTAMP>", # Resource's
"readonly": <BOOLEAN>, # Default=false
"compatibility": "<STRING>", ?
"deprecated": { ... }, ?
"defaultversionid": "<STRING>",
"defaultversionurl": "<URL>",
"defaultversionsticky": <BOOLEAN> ?
}
Meta extension attributes would also appear as additional top-level JSON attributes.
The Meta entity includes the following common attributes:
<RESOURCE>id - REQUIRED in API and document
views. OPTIONAL in requests.self - REQUIRED in API and document views.
OPTIONAL/ignored in requests. References the Meta entity, not the Resource.shortself - OPTIONAL in API and document views,
based on the shortself capability. OPTIONAL/ignored in requests.
References the Meta entity, not the Resource.xid - REQUIRED in API and document views.
OPTIONAL/ignored in requests. References the Meta entity, not the Resource.epoch - REQUIRED in API and document views. OPTIONAL
in requests. This represents the epoch value of the entire Resource,
not of one particular Version. And, it adheres to the normal epoch
processing rules - its value is only updated when the Meta attributes
are updated, but also when a Version is added/removed.labels - OPTIONAL in API and document views..createdat - REQUIRED in API and document views.
OPTIONAL in requests. Creation date of the Resource/Meta entity.modifiedat - REQUIRED in API and document views.
OPTIONAL in requests. Modification date of the Meta entity. This will change
at the same time that epoch changes.deprecated - OPTIONAL. Deprecated state of the
entire Resource.and the following Meta-level attributes:
xref Attribute 🔗Type: XID
Description: Indicates that this Resource is a reference to another Resource within the same Registry. See Cross Referencing Resources for more information.
Constraints:
xid of a same-typed Resource in the Registry.readonly Attribute 🔗Type: Boolean
Description: Indicates whether this Resource is updateable by clients. This attribute is a server-controlled attribute and therefore SHOULD NOT be modifiable by clients. This specification makes no statement as to when Resources are to be read-only.
It is expected that only certain clients (e.g. "admin" clients) would be allowed to edit this attribute. So, for "normal" clients the "SHOULD NOT" statement above is expected to be a "MUST NOT" assertion.
Constraints:
false.true or false.readonly value, in which
case the error MUST be silently ignored, and the Resource MUST remain
unchanged.compatibility Attribute 🔗Type: String (with Resource-specified enumeration of possible values)
Description: States that Versions of this Resource adhere to a certain
compatibility rule. For example, a backward compatibility value would
indicate that all Versions of a Resource are backwards compatible with the
next oldest Version, as determined by their ancestorid attributes.
This specification makes no statement as to which parts of the Version data
are examined for compatibility (e.g. xRegistry metadata, domain-specific
document, etc.). This will be defined by the compatibility rules defined by
each Version's format value.
The exact meaning of what each compatibility value means might vary based
on the format value, therefore this specification only defines a very
high-level abstract meaning for each to ensure some degree of consistency.
However, domain-specific specifications are expected to modify the
compatibility enum values defined in the Resource's model to limit the
list of available values and to define the exact meaning of each.
For compatibility strategies that require understanding the lineage
relationship between the Versions, the ancestorid
attribute on each Version MUST be used to determine that information.
This specification defines the following enumeration values. Implementations MAY choose to extend this list, or use a subset of it.
backward - A Version is compatible with the next oldest Version.backward_transitive - A Version is compatible with all older Versions.forward - A Version is compatible with the next newest Version.forward_transitive - A Version is compatible with all newer Versions.full - A Version is compatible with the next oldest and next newest
Versions.full_transitive - A Version is compatible with all older and all newer
Versions.When not specified, there is no statement being made as to the compatibility
relationship between the Resource's Versions and the server MUST NOT perform
any compatibility checking.
Constraints:
capabilities.compatibilities values
for the set of format values used by the Versions of the Resource.defaultversionid Attribute 🔗Type: String
Description: The versionid of the default Version of the Resource.
This specification makes no statement as to the format of this string or
versioning scheme used by implementations of this specification, other than
it MUST be a valid id Attribute. However, it
is assumed that newer Versions of a Resource will have a "higher" value than
older Versions.
Constraints:
versionid of the default Version of the Resource.When a "patch" type of operation is used and this attribute is present in the
request but defaultversionsticky is absent, then:
null value MUST set defaultversionsticky to true.null value MUST set defaultversionsticky to false.At the end of an update operation, this attribute MUST be set according to the
versionmode value
of the Resource in any of the following situations:
defaultversionsticky value is false.meta sub-object and the request included
defaultversionsticky with a value of true, but no defaultversionid was
provided.meta sub-object and the request modified
defaultversionsticky from false to true, but no defaultversionid
was provided.Regardless of the reason for defaultversionid or defaultversionsticky
being modified, those changes alone MUST NOT change any attributes in any
Version of the owning Resource. For example, attributes such as modifiedat
and epoch of the previous or current default Version remain unchanged.
However, the Resource's meta sub-object's modifiedat and epoch attributes
MUST be updated.
For clarity, when the processing a request that results in
defaultversionsticky being false, then any existing defaultversionid
value, or value specified in the request, MUST be ignored for the purpose of
setting its final value.
Any attempt to set defaultversionid to a non-existing Version, after all
Version processing for the current operation is completed, MUST generate an
error (unknown_id).
See defaultversionsticky Attribute below
for the relationship between these two attribute.
See Default Version of a Resource for more information about the management of default Versions.
1, 2.0, v3-rc1 (v3's release candidate 1)defaultversionurl Attribute 🔗Type: URL
Description: A URL to the default Version of the Resource.
API View Constraints:
self attribute.hasdocument aspect
is set to true, then this URL MUST reference the xRegistry metadata view
of the Version, not the domain-specific document view. In the HTTP
protocol case, this means using the $details suffix.Document View Constraints:
#JSON-POINTER where the JSON-POINTER
locates the default Version within the current document. See
Doc Flag for more information.Examples:
https://example.com/endpoints/ep1/messages/msg1/versions/1.0 (API View)#/endpoints/ep1/messages/msg1/versions/1.0 (Document View)defaultversionsticky Attribute 🔗Type: Boolean
Description: A value of true means that defaultversionid has been
explicitly set and its value MUST NOT automatically change if other Versions
are added or removed. A value of false means the default Version MUST be
the newest Version, as defined by the Resource's
versionmode algorithm.
Constraints:
false.true or false.null MUST be interpreted as a
request to delete the attribute, implicitly setting it to false.maxversions is set to 1, any attempt to set this
this attribute to true MUST generate an error
(setdefaultversionsticky_false) since
setting a default/sticky Version is unnecessary when there can only be
one Version.If a Resource type definition wishes to turn off the ability for clients to
select the "default" Version (or to set the defaultversionsticky attribute to
true), this MAY be done by modifying the definition of this attribute
in the Resource type's model. For example, in the metaattributes section
use the following definition:
"defaultversionsticky": {
"name": "defaultversionsticky",
"enum": [ false ],
"required": true,
"default": false
}
Likewise, forcing all Resource instances to have "sticky" Versions MAY be
achieved via the same mechanism but using true instead of false in the
enum and default aspects.
See defaultversionid Attribute for more
information on the relationship between these two attributes.
See Default Version of a Resource for more information about the management of default Versions.
true, falseVersions represent historical instances of a Resource. When a Resource is
updated, there are two actions that might take place. First, the update can
completely replace an existing Version of the Resource. This is most typically
done when the previous state of the Resource is no longer needed, and there
is no reason to allow people to reference it. The second situation is when
both the old and new Versions of a Resource are meaningful and both might need
to be referenced. In this case, the update will cause a new Version of the
Resource to be created and will have a unique versionid within the scope
of the owning Resource.
For example, updating the data of Resource without creating a new Version
would make sense if there is an error in the description field. But, adding
additional data to the document of a Resource might require a new Version and
a new versionid (e.g. changing it from "1.0" to "1.1").
This specification does not mandate a particular versioning algorithm or
Version identification (versionid) scheme.
When a Version is serialized as xRegistry metadata it MUST adhere to the following:
{
"<RESOURCE>id": "<STRING>", # <SINGULAR>id of Resource
"versionid": "<STRING>",
"self": "<URL>",
"shortself": "<URL>", ?
"xid": "<XID>",
"epoch": <UINTEGER>,
"name": "<STRING>", ?
"isdefault": <BOOLEAN>,
"description": "<STRING>", ?
"documentation": "<URL>", ?
"icon": "<URL>", ?
"labels": { "<STRING>": "<STRING>" * }, ?
"createdat": "<TIMESTAMP>",
"modifiedat": "<TIMESTAMP>",
"ancestorid": "<STRING>",
"contenttype": "<STRING>", ?
"<RESOURCE>url": "<URL>", ? # If not local
"<RESOURCE>": ... Resource document ..., ? # If inlined & JSON
"<RESOURCE>base64": "<STRING>" ? # If inlined & ~JSON
}
Version extension attributes would also appear as additional top-level JSON attributes.
Versions include the following common attributes:
<RESOURCE>id - REQUIRED in API and document
views. OPTIONAL in requests. MUST be the <RESOURCE>id of the owning
Resource.versionid - REQUIRED in API and document views.
OPTIONAL in requests.self - REQUIRED in API and document views.
OPTIONAL/ignored in requests. MUST be a URL to this Version, not the owning
Resource.shortself - OPTIONAL in API and document view,
based on the shortself capability. OPTIONAL/ignored in requests.xid - REQUIRED in API and document views.
OPTIONAL/ignored in requests. MUST be the xid of this Version, not the
owning Resource.epoch - REQUIRED in API and document views. OPTIONAL
in requests. MUST be the epoch value of this Version, not the owning
Resource.name - OPTIONAL.description - OPTIONAL.documentation - OPTIONAL.icon - OPTIONAL.labels - OPTIONAL.createdat - REQUIRED in API and document views.
OPTIONAL in requests.modifiedat - REQUIRED in API and document views.
OPTIONAL in requests.and the following Version-level attributes:
versionid Attribute 🔗Type: String
Description: An immutable unique identifier of the Version.
Constraints:
<SINGULAR>id of the Version.null or request due to these being reserved
for use by the SetDefaultVersionID Flag.meta.defaultversionid value (if defined), otherwise an error
(mismatched_id) MUST be generated.Examples:
1.0v2v3-rcisdefault Attribute 🔗Type: Boolean
Description: Indicates whether this Version is the "default" Version of the owning Resource.
See Creating or Updating Resources and Versions for additional information about this attribute.
Constraints:
false.true or false, case-sensitive.Examples:
truefalseancestorid Attribute 🔗Type: String
Description: The versionid of this Version's ancestor.
The ancestorid attribute MUST be set to the versionid of this Version's
ancestor. If this Version is a root of an ancestor hierarchy tree then it
MUST be set to its own versionid value.
See the Resource's
versionmode model
aspect for more information on how this attribute value can be populated.
If a create operation asks the server to choose the versionid when
creating a root Version, the versionid is not yet known and therefore
cannot be specified in the ancestorid attribute as part of the request. In
those cases a value of request MUST be used as a way to reference itself.
Constraints:
ancestorid attribute MUST NOT be set to a value that
creates circular references between Versions and it is STRONGLY RECOMMENDED
that the server generate an error
(ancestor_circular_reference) if a request
attempts to do so. For example, an operation that makes Version A's
ancestor B, and Version B's ancestor A, would generate an error.ancestorid attribute to a non-existing versionid
MUST generate an error (unknown_id).ancestorid attribute MUST result in
the owning Version's epoch and modifiedat attributes be updated
appropriately, regardless of whether the change to ancestorid was
explicitly part of a request or indirectly changed due to changes to other
Versions.contenttype Attribute 🔗Type: String
Description: The media type of the entity as defined by RFC9110.
Constraints:
<RESOURCE>url attribute. While this specification cannot guarantee that
this attribute's value will match the media type value returned by a
request to retrieve the document at the <RESOURCE>url, it is expected
that they will match.Examples:
application/jsonformat Attribute 🔗Type: String
Description: Identifies what the Version represents. For example, in the case of a Schema Registry, this value would identify the schema format of the Version's domain-specific document. However, it MAY also be used to identify the xRegistry metadata definitions/values for the Version. For example, it could be used to indicate that the Versions are Message definitions.
Managers of the xRegistry instance MAY enforce validation of the data within the Registry by modifying the model to make this a mandatory attribute or by defining a default value.
Constraints:
<NAME>/<VERSION>, whereby <NAME> is
the name of the format and <VERSION> is the version of the format used
by this Version.<NAME> be used for all Versions of a Resource.format validation MUST NOT be performed for that
Version irrespective of the
validateformat
attribute's value.Note: an attempt to set this attribute to a value that differs from the other
Version's values could result in the server rejecting the request due to
the compatibility conformance checks, if
validatecompatibility model attribute is true.
JsonSchema/draft-07Protobuf/3XSD/1.1Avro/1.9formatvalidated Attribute 🔗Type: Boolean
Description: When
format validation
is enabled, this attribute will indicate whether or not the server has
performed validation to ensure the Version conforms to the rules defined by
its format attribute's value.
A value of true indicates that the server has validated the Version and
it adheres to the format attribute's rules. When true the Version's
formatvalidatedreason MUST NOT be
present.
A value of false indicates that the server did not perform validation of
the Version. This can happen when
strictvalidationis set tofalse` and:
format attribute value is not supported by the server.<RESOURCE>url attribute to reference a
domain-specific document stored outside of the Registry. In this case
the server implementation doesn't have access to the document, and
therefore can not verify it, nor does this specification mandate that it
be able to access that URL.When
strictvalidationistrue`, the above conditions MUST generate an error
(format_unknown or format_external) and
reject the update request instead.
When false, the
formatvalidatedreason
MUST be present with an explanation as to why the server was unable to
perform validation of the Version. Additionally, when false, if
compatibility validation is enabled, the Version's
compatibilityvalidated attribute MUST also be
false.
Note that "false" MUST NOT be used for validation failure. In those cases
the write operation MUST generate an error
(format_violation) and reject the request regardless
of the value of the
strictvalidation`
model aspect.
true or false, case-sensitive.validateformat attribute is
true and the Version's format attribute is present.validateformat attribute is
false or the Version's format attribute is absent.formatvalidatedreason Attribute 🔗Type: String
Description: When formatvalidated has a
value of false, this attribute MUST provide information as to why the
format validation check was not performed.
Constraints:
formatvalidated is
present with a value of false.formatvalidated is
absent or has a value of true.compatibilityvalidated Attribute 🔗Type: Boolean
Description: When compatibility
validation
is enabled, this attribute will indicate whether or not the server has
performed validation of the Version conforms to the rules defined by its
Resource's meta.compatibility attribute's value.
A value of true indicates that the server has validated the Version and
it adheres to the meta.compatibility attribute's rules.
A value of false indicates that the server did not perform validation of
the Version. This can happen when
strictvalidationis set tofalse` and:
formatvalidated attribute is false.format or meta.compatibility attributes not supported by the
server.<RESOURCE>url attribute to reference a
domain-specific document stored outside of the Registry. In this case
the server implementation doesn't have access to the document, and
therefore can not verify it, nor does this specification mandate that it
be able to access that URL.When
strictvalidationistrue`, the above conditions MUST generate an error
(format_unknown,
compatibility_unknown or
format_external) and
reject the update request instead.
When false, the
compatibilityvalidatedreason
MUST be present with an explanation as to why the server was unable to
perform validation of the Version.
Note that false MUST NOT be used for validation failure. In those cases
the write operation MUST generate an error
(compatibility_violation) and reject the request
regardless of the value of the
strictvalidation`
model aspect.
Constraints:
true or false, case-sensitive.validatecompatibility attribute
is true, the Version's format value is present, and the Resource's
meta.compatibility attribute is present.validatecompatibility
attribute is false, or the Version's format value is absent, or the
Resource's meta.compatibility attribute is absent.compatibilityvalidatedreason Attribute 🔗Type: String
Description: When
compatibilityvalidated has a
value of false, this attribute MUST provide information as to why the
format validation check was not performed.
Constraints:
compatibilityvalidated is
present with a value of false.compatibilityvalidated is
absent or has a value of true.<RESOURCE>url Attribute 🔗Type: URI
Description: If the Version's domain-specific document is stored outside of the current Registry, then this attribute MUST contain a URL to the location where it can be retrieved. If the value of this attribute is a well-known identifier that is readily understood by registry clients and resolves to a common representation of the Version, or an item in some private store/cache, rather than a networked document location, then it is RECOMMENDED for the value to be a uniform resource name (URN).
Constraints:
hasdocument aspect
is set to false.<RESOURCE> Attribute 🔗Type: Resource Document
Description: This attribute is a serialization of the corresponding Version's domain-specific document's contents. If the document's bytes "as is" (without any additional processing such as escaping) allows for them to appear as the value of this JSON attribute, then this attribute MUST be used if the request asked for the document to be inlined in the response.
This is a convenience (optimization) attribute to make it easier to view the document when it happens to be in the same format as the serialization of the Version.
The model Resource attribute
typemap
MAY be used to help the server determine if the document is in the
same format. If a Version has a matching contenttype attribute but the
contents of the Version's document do not successfully parse (e.g. it's
application/json but the JSON is invalid), then <RESOURCE>
MUST NOT be used and <RESOURCE>base64 MUST be used instead.
Constraints
<RESOURCE> or <RESOURCE>base64 MUST be present.<RESOURCE>base64 is also present.hasdocument aspect
is set to false.<RESOURCE>base64 Attribute 🔗Type: String
Description: This attribute is a base64 encoding of the corresponding
Version's domain-specific document. If the Version's document (which is
stored as an array of bytes) is not conformant with the format being used
to serialize the Version (e.g. as a JSON value), then this attribute MUST be
used instead of the <RESOURCE> attribute.
Constraints:
<RESOURCE> or <RESOURCE>base64 MUST be present.<RESOURCE>base64 MUST be present with an empty string ("") value.<RESOURCE> is also present.hasdocument aspect
is set to false.When accessing a Versions's xRegistry metadata, often it is to
view or update the xRegistry metadata and not the document, as such, including
the potentially large amount of data from the Version's document in request
and response messages could be cumbersome. To address this, the <RESOURCE>
and <RESOURCE>base64 attributes do not appear by default as part of the
serialization of the Version. Rather, they MUST only appear in responses when
the Inline Flag, with a value of <RESOURCE>, is used.
Likewise, in requests, these attributes are OPTIONAL and would only need to be
used when a change to the document's content is needed at the same time as
updates to the Version's metadata. However, the <RESOURCE>url attribute MUST
always appear if it has a value, just like any other attribute.
Note that the serialization of a Version MUST only use at most one of these 3 attributes at a time.
Client and server implementations MUST be prepared for any of these 3
attributes to be used. In the case of <RESOURCE> or <RESOURCE>base64,
implementations can not assume that a previous use of one means that all
subsequent messages of that entity will use the same attribute. For example,
a client can use <RESOURCE> to populate the value, but the server is free
to use <RESOURCE>base64 when returning the data.
If a server does not support client-side specification of the versionid of a
new Version (see the
setversionid aspect
in the Registry Model), or if a client chooses to
not specify the versionid, then the server MUST assign new Versions a
versionid that is unique within the scope of its owning Resource.
Servers MAY have their own algorithm for the creation of new Version
versionid values, but the default algorithm is as follows:
versionid MUST be a string serialization of a monotonically increasing
(by 1) unsigned integer starting with 1 and is scoped to the owning
Resource.versionid is needed, if an existing Version already has
that versionid then the server MUST generate the next versionid value
and try again.1 each time, it MUST
continue from the highest previously generated value.With this default versioning algorithm, when semantic versioning is needed,
it is RECOMMENDED to include a major version identifier in the Resource
<RESOURCE>id, like "com.example.event.v1" or "com.example.event.2024-02",
so that incompatible, but historically related Resources can be more easily
identified by users and developers. The Version's versionid then functions
as the semantic minor version identifier.
As Versions of a Resource are added or removed, there needs to be a mechanism by which the "default" one is determined. There are two options for how this might be done:
Default = Newest. The newest Version (based on the Resource's
versionmode
algorithm) MUST become the "default" Version. This is the default choice.
Client explicitly chooses the "default". In this option, a client has explicitly chosen which Version is the "default" and it MUST NOT change until a client chooses another Version - this is referred to as the default Version being "sticky". When the current default Version is deleted and the client did not specify which Version is to become the next default Version (see below), then the server MUST revert back to option 1 (default = newest).
A client MAY choose the "default" Version two ways:
defaultversionsticky and
defaultversionid attributes
in its meta sub-object.See defaultversionid and
defaultversionsticky attributes for more
information.
Each protocol binding will define how to delete entities, and in most cases the operation will be straight-forward since the action will likely either be a "delete" operation directed to the entity in question, or in the case of deleting multiple entities, it will be directed to the owning collection along with a map of entity IDs to be deleted.
When deleting multiple entities, the list of entities to delete MUST be specified as a map. There will be 3 possible ways in which the map will be serialized:
1 - Deleting multiple entities (no epoch value checking)
{
"<KEY>": {} # <SINGULAR>id of entity
} ?
While this could have been represented as an array of IDs, for consistency with the next two variants, and with what a query for the list of entities in a collection will return, it's a map.
2 - Deleting multiple non-Resource entities with epoch value checking
{
"<KEY>": { # <SINGULAR>id of entity
"epoch": <UINTEGER> ?
} *
} ?
Since each entity now has an epoch value associated with it, the server MUST
perform epoch value checking and reject the entire request if any fail. This
is similar to what an "update" operation would look like.
3 - Deleting multiple Resource entities with epoch value checking
{
"<KEY>": { # <SINGULAR>id of Resource
"meta": {
"epoch": <UINTEGER> ?
} ?
} *
} ?
Since a Resource's epoch value is part of its meta entity, and not a
top-level Resource attribute, for consistency with what the retrieval of
a Resource would look like, the epoch value in this case MUST appear under
a meta entity within the Resource. And the normal epoch value checking
rules would apply.
This special serialization rules for Resources was done because an epoch
value that appears as a top-level attribute is likely done when a client
mistakenly uses a Version's serialization rather than the owning Resource's.
If an epoch value only appears at the top-level (and not within meta) then
an error (misplaced_epoch) MUST be generated.
If epoch appears in both places then the top-level one MUST be silently
ignored.
Regardless of type of "delete" being done, the following rules apply:
<SINGULAR>id of the entity to be deleted.<SINGULAR>id is present in the request, then it MUST
match its corresponding <KEY> value, other a
mismatched_id MUST be generated.This specification allows for clients to configure server-side processing via the use of "flags" (configuration options) on requests. The allowable flags might vary based on the specific operation being performed, and some will influence the processing of the request while some will influence the how the response message will be generated.
Implementations of this specification SHOULD support all specification-defined flags.
The following sections define each flag and then the protocol-specific specifications will indicate how they are to be serialized on each request:
See: Request Flags in the HTTP binding specification for the HTTP usage.
The binary flag MAY be used on requests to indicate that the server MUST use
the <RESOURCE>base64 attribute instead of the <RESOURCE> attribute when
serializing any Resource's domain-specific document in the response message.
Note, the presence of this flag does not change when the document is inlined,
just how it is serialized if it is inlined.
This flag is intended for cases where the client wishes to avoid the server modifying the bytes of the document in any way - such as "pretty printing" it.
This flag MAY be used on any request but will only influence the serialization of Resource and Version entities that have a domain-specific document.
The collections flag MAY be used on requests directed to the Registry itself,
or to Group instances, to indicate that the response message MUST NOT include
any attributes from the top-level entity (Registry or Group), but instead MUST
include only all of the nested xRegistry Collection maps that are defined at
that level. Specifying it on a request directed to some other part of the
Registry MUST generate an error (bad_flag). Use of this flag MUST
implicitly turn on inlining within a value of *.
Servers MAY choose to include, or exclude, the sibling <COLLECTION>url and
<COLLECTION>count attributes for those top-level collections.
Note that this feature only applies to the root entity of the response and not to any nested entities/collections.
This feature is meant to be used when the Collections of the Registry, or Group, are of interest but not the top-level metadata. For example, this could be used to export one or more Group types from a Registry where the resulting JSON document is then used to import them into another Registry. If the Registry-level attributes were present in the output then they would need to be removed prior to the import, otherwise they would override the target Registry's values.
A query result when using this feature is designed to be used on a future "write" operation to a Registry (or Group) where the nested Collections are to be updated without modifying the attributes of the root entity of the operation.
For example, to export all of the Groups of one Registry into another, without modifying the Registry entity's attributes, can be done via HTTP by taking the results from:
GET http://sourceRegistry.com/?collections
and using it as input into:
POST http://targetRegistry.com/
The doc flag MAY be used to indicate that the response MUST use "document
view" when serializing entities and MUST be modified to do the following:
formatvalidated and compatibilityvalidated
attributes from Version serializations.shortself attribute from all entity serializations.xref feature, the target Resource's
attributes MUST be excluded from the source's serialization.self, <COLLECTION>url, metaurl, defaultversionurl.All of the relative URLs mentioned in the last bullet above MUST begin with #
and be followed by a
JSON Pointer reference to the
entity within the response, e.g. #/endpoints/e1. This means that they are
relative to the root of the document (response) generated, and not necessarily
relative to the root of the Registry. Additionally, when those URLs are
relative and reference a Resource or Version, any protocol-specific
modifications to the URLs (e.g. the HTTP $details suffix) MUST NOT be
present despite the semantics of the suffix being applied (as noted below).
For clarity, if a Registry has a Schema Resource at
/schemagroups/g1/schemas/s1, then this entity's self URL (when serialized
in document view) would change based on the path specified on the GET
request:
| GET Path | self URL |
|---|---|
http://example.com/myreg |
#/schemagroups/g1/schemas/s1 |
http://example.com/myreg/schemagroups |
#/g1/schemas/s1 |
http://example.com/myreg/schemagroups/g1/ |
#/schemas/s1 |
http://example.com/myreg/schemagroups/g1/schemas |
#/s1 |
http://example.com/myreg/schemagroups/g1/schemas/s1 |
#/ |
This feature is useful when a client wants to minimize the amount of data returned by a server because the duplication of that data (typically used for human readability purposes) isn't necessary. For example, if tooling would ignore the duplication, or if the data will be used to populate a new Registry, then this feature might be used. It also makes the output more of a "stand-alone" document that minimizes external references.
For clarity, the serialization of a Resource in document view MUST adhere to the following:
{
"<RESOURCE>id": "<STRING>",
"self": "<URL>",
"shortself": "<URL>", ?
"xid": "<XID>",
"metaurl": "<URL>",
"meta": {
"<RESOURCE>id": "<STRING>",
"self": "<URL>",
"shortself": "<URL>", ?
"xid": "<XID>",
"xref": "<XID>" ?
# The following attributes are absent if 'xref' is set
"epoch": <UINTEGER>,
"labels": { "<STRING>": "<STRING>" * }, ?
"createdat": "<TIMESTAMP>",
"modifiedat": "<TIMESTAMP>",
"readonly": <BOOLEAN>,
"compatibility": "<STRING>",
"deprecated": { ... }, ?
"defaultversionid": "<STRING>",
"defaultversionurl": "<URL>"
"defaultversionsticky": <BOOLEAN> ?
}
}
Note that the meta entity's attributes epoch through
defaultversionsticky MUST be excluded if xref is set because those would
appear as part of the target Resource's meta entity. Also notice
the default Version's attributes do not appear.
If this flag is used on a request directed to a Resource's versions
collection, or to one of its Versions, but the Resource is defined as an
xref to another Resource, then the server MUST generate an error
(cannot_doc_xref) and SHOULD indicate that using this
flag on this part of the hierarchy is not valid - due to those entities not
technically existing in document view.
The epoch flag MAY be used on any delete operation directed to a single
entity if the protocol being used doesn't normally include the serialization
of the "to be deleted" entity in the request. In those cases, this flag is
used to request that the entity's current epoch value matches this flag's
value for the purpose of the server's
epoch conflict checking algorithm.
The filter flag MAY be used to indicate that the response MUST include only
those entities that match the specified filter criteria expressions. This
means that any Registry Collection's attributes MUST be modified to match the
resulting subset. In particular:
url attribute MUST include the appropriate filter
expression(s) such that a query to that URL would return the same subset of
entities, if the protocol supports including the filter flag value as part
of the URL.count attribute MUST only count the entities that match the
filter expression(s).Parameters to this flag include one or more filter expressions. Each protocol binding will indicate how to express logical ANDs and ORs between those expressions. Regardless of how it is expressed the following rules apply:
The format of a filter expression is one of:
[<PATH>.]<ATTRIBUTE>
[<PATH>.]<ATTRIBUTE>=null
[<PATH>.]<ATTRIBUTE>=[<VALUE>]
[<PATH>.]<ATTRIBUTE><<VALUE>
[<PATH>.]<ATTRIBUTE><=<VALUE>
[<PATH>.]<ATTRIBUTE>><VALUE>
[<PATH>.]<ATTRIBUTE>>=<VALUE>
[<PATH>.]<ATTRIBUTE>!=<VALUE>
[<PATH>.]<ATTRIBUTE><><VALUE>
Where:
<PATH> MUST be a dot (.) notation traversal
of the Registry to the entity of interest, or absent if at the top of the
Registry request. See the
xRegistry Dot (.) Notation section for more
details on the syntax.<PATH> value MUST be based on the requesting URL and not the root of
the Registry. Meaning, if the URL targets a Group then the <PATH> value
would be relative to the Group and not the root of the Registry. See the
examples below.<ATTRIBUTE> uses dot notation as well. Technically, the filter expression
is a single dot notation reference, but the <PATH> and <ATTRIBUTE> are
called out separately here for descriptive purposes.<ATTRIBUTE> MUST be the attribute in the entity to be examined.null <VALUE> MUST only be used when referencing scalar attributes.myobj.myattr=5 would not match if: myobj is missing,
myattr is missing, or myattr is not 5.<ATTRIBUTE> present with any non-null
value.= operator:
<VALUE> is null then only entities without the specified
<ATTRIBUTE> MUST be included in the response.null <VALUE> is specified then <VALUE> MUST be the
desired value of the attribute being examined. Only entities whose
specified <ATTRIBUTE> with this <VALUE> MUST be included in the
response.<VALUE> is absent then the implied <VALUE> is an empty string
and the matching MUST be done as specified in the previous bullet.!=, <> operators:
<VALUE> is null then it MUST have the same semantics as a
filter expression of <ATTRIBUTE> as specified above (meaning, present
with any non-null value).<VALUE> is non-null then only entities without the specified
<ATTRIBUTE> and <VALUE> MUST be included in the response. This MUST
be semantically equivalent to NOT(<ATTRIBUTE>=<VALUE>), and this also
means that if <ATTRIBUTE> is missing then that attribute will match
the filter.<, <=, >, >= operators:
<VALUE> MUST NOT be null.<ATTRIBUTE> and <VALUE> that matches
the comparison operator's semantics MUST be included in the response.< refers to "less than".<= refers to "less than or equal to".> refers to "greater than".>= refers to "greater than or equal to".*) (see below) MUST NOT be present in the <VALUE>.For comparing an <ATTRIBUTE> to the specified <VALUE>, and for purposes
of sorting (see the Sort flag), the type of the attribute
impacts how the comparisons are done:
true or false). For relative comparisons, false is less than true.See the Sort section for more details concerning sorting.
Additionally, wildcards (*) MAY be used in string <VALUE>s with the
following constraints:
=, != or <>.<VALUE>.\\) character
(e.g. abc\*def) to mean that the * is to be interpreted as a normal
character and not as a wildcard.<VALUE> of * MUST be equivalent to checking for the existence of the
attribute, with any value (even an empty string). In other words, the filter
will only fail if the attribute has no value at all.As specified in the Registry Collections section,
when a query includes a filter expression, any nested xRegistry collections
in the response SHOULD result in the specification of a <COLLECTION>url
attribute that allows clients to easily traverse into that collection with
the appropriated sub-filter expression to yield the same results as the
original filter, but just for that nested collection. However, if the filters
results in zero entities for a particular collection due to the filter
excluding that collection entirely, rather than the <COLLECTION>url not
having any filter expression at all (which would result in the full collection
being returned), servers MUST use the special filter expression excludeall
to indicate no results are to be returned for that URL.
For example, using HTTP:
GET /?filter=schemagroups.schemas.name=myschema
HTTP/1.1 200 OK
Content-Type: application/json; charset=utf-8
{
... Registry attributes excluded for brevity ...
"messagegroupsurl": "http://example.com/messagegroups?filter=excludeall",
"messagegroupscount": 0,
"schemagroupsurl": "http://example.com/schemagroups?filter=schemas.name=myschema",
"schemagroupscount": 10
}
If the URL references a collection then an empty collection ({}) MUST be
returned. If the URL references an entity, then an error
(not_found) MUST be generated. If any other filter expression
appear at the same time, then an error (bad_filter) MUST be
generated.
The special filter value excludeall MAY be used to indicate that no
results are to be returned from the query. This value is expected to only be
used by servers in response to a query that produces a <COLLECTION>url.
If the request references an entity (not a collection), and the expression
references an attribute in that entity (i.e. there is no <PATH>), then if the
expression does not match the entity, that entity MUST NOT be returned. In
other words, a 404 Not Found would be generated in the HTTP protocol case.
Invalid filter expressions MUST generate an error (bad_filter).
Examples:
Using the HTTP protocol binding syntax:
| Request Path | Filter query | Commentary |
|---|---|---|
| / | ?filter=endpoints.description=*cool* |
Only endpoints with the word cool in the description |
| /endpoints | ?filter=description=*CooL* |
Similar results as previous, with a different request URL |
| / | ?filter=endpoints.messages.versions.versionid=1.0 |
Only versions (and their owning parents) that have a versionid of 1.0 |
| / | ?filter=endpoints.name=myendpoint,endpoints.description=*cool*& filter=schemagroups.labels.stage=dev |
Only endpoints whose name is myendpoint and whose description contains the word cool, as well as any schemagroups with a label name/value pair of stage/dev |
| / | ?filter=description=no-match |
Returns a 404 if the Registry's description doesn't equal no-match |
| / | ?filter=endpoints.messages.meta.readonly=true |
Only messages that are readonly |
Specifying a filter does not imply inlining. Inlining MAY be used at the same time but MUST NOT result in additional entities being included in the results unless they are children of a matching leaf entity.
For example, in the following entity URL paths representing a Registry:
mygroups/g1/myresources/r1/versions/v1
mygroups/g1/myresources/r1/versions/v2
mygroups/g1/myresources/r2/versions/v1
mygroups/g2/myresources/r3/versions/v1
This HTTP request:
GET /?filter=mygroups.myresources.myresourceid=r1&inline=*
would result in the following entities (and their parents along the specified paths) being returned:
mygroups/g1/myresources/r1/versions/v1 # versions are due to inlining
mygroups/g1/myresources/r1/versions/v2
However, this request:
GET /?filter=mygroups.mygroupid=g2&filter=mygroups.myresources.myresourceid=r1&inline=*
would result in the following returned:
mygroups/g1/myresources/r1/versions/v1 # from 2nd ?filter
mygroups/g1/myresources/r1/versions/v2 # from 2nd ?filter
mygroups/g2/myresources/r3/versions/v1 # from 1nd ?filter
And, this request:
GET /?filter=mygroups.mygroupid=g1&filter=mygroups.myresources.myresourceid=r1&inline=*
would result in the following being returned:
mygroups/g1/myresources/r1/versions/v1 # from 2nd ?filter
mygroups/g1/myresources/r1/versions/v2 # from 2nd ?filter
mygroups/g1/myresources/r2/versions/v1 # from 1st ?filter
And, finally this request:
GET /?filter=mygroups.mygroupid=g1,mygroups.myresources.myresourceid=r1&inline=*
would result in the following being returned:
mygroups/g1/myresources/r1/versions/v1
mygroups/g1/myresources/r1/versions/v2
Notice the first part of the filter expression (to the left of the "and"
(,)) has no impact on the results because the list of resulting leaves in
that subtree is not changed by that search criteria.
The ignore flag MAY be used on any write operation to indicate that certain
parts of the request message MUST be ignored by the server. This flag is
designed for cases where a user wants to import data into a Registry without
going through the (potentially tedious) process of removing certain parts of
the data in advance. Typically, in an "export->import" scenario.
This flag take a list of strings indicating which aspects of the request message to ignore. This specification defines the following values:
capabilities
This value indicates that any capabilities attribute included in the
request MUST be ignored.
defaultversionid
This value indicates that any defaultversionid attribute included in the
request MUST be ignored.
defaultversionsticky
This value indicates that any defaultversionsticky attribute included in
the request MUST be ignored.
epoch
This value indicates that any epoch attribute included in the request MUST
be ignored.
id
When this value is used then any <SINGULAR>id present in the root entity
MUST be ignored, and any validation to ensure it matches the targeted
entity's existing <SINGULAR>id value MUST NOT be performed.
This feature MUST only apply in cases where the request is targeted to a single entity not a collection.
This features is design for cases where an entity is exported and then used
as input for another entity where that targeted entity needs to use a
different <SINGULAR>id for the root entity, without needing to transform
the exported data.
Note that any nested entities in the request MUST retain their <SINGULAR>id
values.
In cases where the target entity is a Version, then the flag MUST apply to
both the Resource's <SINGULAR>id and the versionid.
modelsource
This value indicates that any modelsource attribute included in the request
MUST be ignored.
readonly
This value indicates that any attempt to modify a read-only Resource MUST be silently ignored as if the Resource in question was never included in the request. Usage of this value in situations where removing the Resource from the request would invalidate the syntax or semantics of the request MUST generate an error (bad_flag).
To clarify its usage consider the following scenarios:
ignore set to readonly directed to an
individual read-only Resource would generate an error because removing
the Resource from the request invalidates the validity of the request.ignore set to readonly directed to a
Resource collection would ignore the read-only Resources referenced in the
collection map (conceptually removing them from the request), and the
request would still be valid (syntactically and semantically), even if the
resulting map is empty. The request would not generate an error due to the
usage of this flag.Implementations MAY defined additional values.
Specifying the flag without any values, an empty string, or * indicates a
request to ignore all possible (server supported) aspects of the request
message.
Specifying an invalid, or unsupported, value for this flag MUST generate an error (bad_ignore).
The inline flag MAY be used on requests to indicate whether nested
collections/objects, or certain (potentially large) attributes, are to be
included in the response message.
The inline flag on a request indicates that the response MUST include the
contents of all specified inlineable attributes. Inlineable attributes include:
model attribute on the Registry entity.modelsource attribute on the Registry entity.capabilities attribute on the Registry entity.<GROUPS>,
<RESOURCES> and versions.<RESOURCE> attribute in a Resource or Version.meta attribute in a Resource.Specifying the name of a non-inlineable attribute MUST generate an error (inline_noninlineable).
While the <RESOURCE> and <RESOURCE>base64 attributes are defined as two
separate attributes, they are technically two separate "views" of the same
underlying data. As such, the usage of each will be based on the content type
of the Resource, and specifying <RESOURCE> in the inline flag value
MUST be interpreted as a request for the appropriate attribute. In other words,
<RESOURCE>base64 is not a valid inline value.
Use of this feature is useful for cases where the contents of the Registry are to be represented as a single (self-contained) document.
Some examples using the HTTP protocol binding:
GET /?inline=model # Just 'model'GET /?inline=model,endpoints # Model and one level under endpointsGET /?inline=* # Everything except 'model','modelsource','capabilities'GET /?inline=model,* # Everything, including 'model'GET /?inline=endpoints.messages # One level below 'endpoints.messages'GET /?inline=endpoints.* # Everything below 'endpoints'GET /endpoints/ep1/?inline=messages.message # Just 'message'GET /endpoints/ep1/messages/msg1?inline=message # Just 'message'The value of the inline flag is a list of <PATH> values where each is a
string indicating which inlineable attribute to show in the response.
References to nested attributes are represented using a
dot (.) notation where the xRegistry collection
names along the hierarchy are concatenated. For example:
endpoints.messages.versions will inline all Versions of Messages. Non-leaf
parts of the <PATH> MUST only reference xRegistry collection names and not
any specific entity IDs since <PATH> is meant to be an abstract traversal of
the model.
There MAY be multiple <PATH>s specified in a single request and each
protocol binding specification will indicate how the list is specified.
The * value MAY be used to indicate that all nested inlineable attributes
at that level in the hierarchy (and below) MUST be inlined - except model,
modelsource and capabilities at the root of the Registry. These three are
excluded since the data associated with them are configuration related. To
include their data the request MUST include <PATH> values of model,
modelsource or capabilities explicitly. Use of * MUST only be used as
the last part of the <PATH> (in its entirety). For example, foo* and
*.foo are not valid <PATH> values, but * and endpoints.* are.
An inline flag without any value MAY be supported and if so it MUST have the
same semantic meaning as a value of *.
The specific value of <PATH> will vary based on where the request is
directed. For example, a request to the root of the Registry MUST start with a
<GROUPS> name, while a request directed at a Group would start with a
<RESOURCES> name.
For example, given a Registry with a model that has endpoints as a Group and
messages as a Resource within endpoints, the table below shows some
<PATH> values and a description of the result for the HTTP protocol:
HTTP GET Path |
Example ?inline=<PATH> values |
Comment |
|---|---|---|
| / | ?inline=endpoints | Inlines the endpoints collection, but just one level of it, not any nested inlineable attributes |
| / | ?inline=endpoints.messages.versions | Inlines the versions collection of all messages. Note that this implicitly means the parent entities (messages and endpoints would also be inlined - however any other <GROUPS> or <RESOURCE>s types would not be |
| /endpoints | ?inline=messages | Inlines just messages and not any nested attributes. Note we don't need to specify the parent <GROUP> since the URL already included it |
| /endpoints/ep1 | ?inline=messages.versions | Similar to the previous endpoints.messages.version example |
| /endpoints/ep1 | ?inline=messages.message | Inline the Resource document |
| /endpoints/ep1 | ?inline=endpoints | Invalid, already in endpoints and there is no <RESOURCE> called endpoints |
| / | ?inline=endpoints.messages.meta | Inlines the meta entity of each message returned. |
| / | ?inline=endpoints.* | Inlines everything for all endpoints. |
Note that asking for an attribute to be inlined will implicitly cause all of its parents to be inlined as well, but just the parent's collections needed to show the child. In other words, just the collection in the parent in which the child appears, not all collections in the parent.
When specifying a collection to be inlined, it MUST be specified using the plural name for the collection in its defined case.
A request to inline an unknown, or non-inlineable, attribute MUST generate an error (bad_inline).
Note: If the Registry cannot return all expected data in one response because it is too large then it MUST generate an error (too_large). In those cases, the client will need to query the individual inlineable collection attributes in isolation so the Registry can leverage a pagination type of feature to iteratively retrieve the entities.
The setdefaultversionid flag MAY be used on any write operation directed to
a single Resource, its meta sub-object or its Versions. The primary use case
is one in which the current default Version is being deleted and the client
wishes to choose a new default Version at the same time - to avoid an incorrect
one being chosen temporarily.
Use of this flag on an operation that allows for modifying multiple Resources MUST generate an error (bad_flag).
This flag MUST include a single parameter, a string containing the versionid
of the Version that is to become the new default Version.
The following rules apply:
null indicates that the client wishes to switch to the
"default = newest" algorithm, in other
words, the "sticky" aspect of the current default Version will be removed
and meta.defaultversionsticky MUST be set to false.versionid value for the new Version, then including that value as the
setdefaultversionid value is not possible. In those cases a value of
request MAY be used as a way to reference that new Version.request MUST only be used on APIs that allow the creation of
only a single new Version. In the case of HTTP, that is the POST API
directed to a Resource. This is because no other operation allows for the
creation of a single Version without specifying its versionid. Using it
when more than one Version is created MUST generate an error
(too_many_versions). Other uses of this value on an
inappropriate API MUST generate an error (bad_flag).request was used but no Version was created for the request,
then an error (defaultversionid_request) MUST
be generated.null and non-request value does not reference an existing
Version of the Resource, after all Version processing is completed, then an
error (unknown_id) MUST be generated.meta.defaultversionid to a non-empty value via this flag MUST
also set the meta.defaultversionsticky attribute to true.meta.defaultversionid and
meta.defaultversionsticky values that are present in the request.Any other invalid usage of this flag MUST generate an error (bad_defaultversionid).
When a request is directed at a collection of Groups, Resources or Versions,
the Sort flag MAY be used to indicate the order in which the entities of
that collection are to be returned (i.e. sorted). Use of the sort flag
on a non-collection result MUST generate an error
(sort_noncollection).
This flag MUST include a single parameter, a string containing the attribute
(<ATTRIBUTE>) name to use as the "sort key" plus an OPTIONAL indication of
whether the results are to be sorted in ascending or descending order.
The following rules apply:
<ATTRIBUTE> MUST be a dot (.) notation path
to one of the attributes defined in collection's entities that will be the
primary sort key for the results.
The attribute MUST only reference a scalar attribute within the top-level
collection, it MUST NOT attempt to traverse into a nested xRegistry
collection even if that nested collection is inlined.asc for ascending, desc for descending) MAY
be specified to indicate whether the first entity in the returned collection
MUST be the "lowest" values (asc) or whether it MUST be the "highest"
value (desc). When not specified, the default value MUST be asc.If the specified attribute is not found within the entities being sorted then
implementations SHOULD treat that entity's sort-key value as NULL.
When a pagination type of feature is used to return the results, but
the sort flag is not specified, then the server MUST sort the results on the
entities' <SINGULAR>id value in ascending order. When pagination is not used,
it is RECOMMENDED that servers still sort the results by <SINGULAR>id (asc)
for consistency.
Sorting MUST be done using the data type comparison rules as specified in the
filter Flag section. However, there are certain situations
that might introduce ambiguity between implementations. For example, not all
persistent stores support NaNs (Not-a-Number values), or if the data type of
an attribute changes on a per-instance basis then consistent sorting across
implementations on that attribute might be challenging. While interoperability
is critical, requiring consistency in these edge cases could be excessively
burdensome for implementations. To that end, this specification does not
mandate the exact ordering in these situations, aside from the requirement
that an implementation MUST sort the result the same way each time.
Entities that do not have a value for the specified attribute MUST be treated
the same as if they had the "lowest" possible value for that attribute. If
more than one entity shares the same attribute value then the <SINGULAR>id
MUST be used as a secondary sorting key, using the same asc/desc value
specified for the primary sorting key.
An invalid usage of, or value for, the sort flag MUST generate an error
(bad_sort).
Some examples using the HTTP protocol binding:
GET /endpoints?sort=name # Sort (asc) on 'name', then 'endpointid'GET /endpoints/e1/messages?sort=messageid=desc # Sort (desc) on 'messageid'GET /endpoints?sort=labels.stage # Sort (asc) on labels.stage, then endpointidThe SpecVersion flag MAY be used to indicate the xRegistry specification version that the response MUST adhere to. The parameter value of this flag MUST be a case-insensitive string.
If the specified version is not supported, then an error (unsupported_specversion) MUST be generated. When not specified, the default value MUST be the newest version of this specification supported by the server.
When comparing specversion strings, the server MUST silently ignore the
"patch" version number and only consider the "major.minor" version numbers.
This is because any "patch" version updates will only contain clarifications
and ought not require any code changes for server implementations. Therefore,
all patch versions of the same "major.minor" version MUST be forwards and
backwards compatible.
However, due to the potential for semantics changes of versions with suffix
values (e.g. v2.0.0-rc1), the suffix value MUST be part of the comparison
checking.
.) Notation 🔗This specification defines a syntax for referencing entities and attributes within the xRegistry metadata. Known as "dot notation", it borrows some of the core aspects of the JSON Path specification.
The following notation operators are defined:
.NAME : access a property (or key) of an object (or map).['NAME'] : same as previous but NAME contains characters that are not
to be interpreted as an operator (e.g. .) or it contains just digits and
is not to be interpreted as an array index.["NAME"] : same as previous but with double-quotes (").[INTEGER] : access an array index (zero-based).Note: due to the serialization of maps and objects (often) being indistinguishable, this specification (similar to JSONPath) does not provide different syntaxes for traversing each.
For clarity, use of square brackets ([]) without use of either type of
quotes around the value MUST be interpreted as accessing an array. Conversely,
use of quotes MUST be interpreted as accessing an object/map.
Examples:
| Dot Notation | Description |
|---|---|
.name |
An attribute (or map key) called name |
['my.name'] |
An attribute (or map key) called my.name |
[2] |
The 3rd (zero-based) item in an array |
["birth.date"] |
Attribute/key called birth.date |
["2"] |
An attribute/key called 2 (a string, not integer) |
employee.name |
name attribute/key in an object/map called employee |
stack[3] |
Element with index 3 (zero-based) in stack array |
employee['joe'].addresses[0].state |
joe attr/key of employee, then the first index of its addresses array, then state attr/key of that address |
Depending on the situation in which the notation is being used, there are certain special values that MAY be used, a described in the following sections.
When using filters the following special values MAY be used:
.* |
Match any item in an object/map |
[*] |
Match any item in an array |
Note that ['*'] is not the same as .*. Rather, ['*'] is a reference
to an attribute/key called * - assuming that it is a valid attribute/key
name in that particular situation.
Examples
Given the following definition of a schemagroup Group type extension:
{
"info": {
"owner": <STRING>,
"reviewers": [ <STRING>, * ] # An array of strings
"labels": { "<STRING>": "<STRING>" * }, ? # A map of string -> string
"addresses": {
"<STRING>": { # e.g. "home", "work"
"street": "<STRING>",
"state": "<STRING>",
"zip": "<STRING>"
} *
} *
},
"age": <INTEGER>
}
age of 5:
GET /?filter=schemagroups.age=5owner is joe:
GET /?filter=schemagroups.info.owner=joeenv set to prod:
GET /?filter=schemagroups.info.labels.env=propJune:
GET /?filter=schemagroups.info.labels.*=JuneSteve:
GET /?filter=schemagroups.info.reviewers[*]=SteveCA:
GET /?filter=schemagroups.info.addresses.*.state=CAIn the above examples, notice that the filter only specified the schemagroups
collection as part of the hierarchy traversal. From a purist perspective those
filters really ought to have been written with the * wildcard for the
matching schemagroups's ID, for example:
?filter=schemagroups.*.info.owner
to indicate that we're asking to search over all schemagroups (by ID) in the
schemagroups collection, and then for each one examine its info.owner
attribute. However, requiring that extra bit of information in the filter
would introduce two potential problems:
.*. in almost all filter expressions,
which could be tedious since in most cases it's expected that people are
going to search over all items in the xRegistry collection.GET /schemagroups/mygroup/... - in which case the ID would
not appear as part of the filter expression at all.As a result, when specifying a filter expression that steps between the
xRegistry hierarchy, the ID portion of the path is excluded. However, this
does not apply to stepping through the path of objects/maps/arrays defined
within an xRegistry entity (Group, Resource, Versions). In those cases use
of the * wildcard would need to be used to indicate "any" items in that set.
This is demonstrated in the "info.addresses" example above.
For completeness, to filter based on a schema's name, the request might look like:
GET /?filter=schemagroups.schemas.name=myschema
would search over all schemagroups, and over all schemas in those groups,
for ones with a name attribute set to myschema.
It is worth noting that if the user really does want a certain schemagroup with
a certain ID (e.g. mygroup), without the request URL path being
/schemagroups/mygroup, then they can achieve this by using a compound
filter:
GET /?filter=schemagroups.schemas.name=myschema,schemagroups.schemagroupid=mygroup
The , in a single filter expression represents an AND operation.
The dot-notation defined in this specification is purposely limited to keep implementation requirements to a minimum. However, third-party xRegistry tooling might leverage more expressive dot-notation features. In order to encourage interoperability and consistency across tooling, the following syntax guidelines are RECOMMENDED for other common situations:
[INTEGER:].
set myarray[3:]=mary would be used to insert "mary" at the 4th
index (zero-based), pushing current index positions 3 (and higher) further
down in the array.0 for an empty array.[^].
set myarray[^]=mary would insert "mary" at the start of the array,
and create the array first if it is not yet defined.[$].
set myarray[$]=mary would append "mary" to the end of the array,
and create the array first if it is not yet defined.[-1].
set myarray[-1]=mary would replace the last item in the array.{}.
set myobject={} would replace any value for myobject with an
empty object/map.[].
set myarray=[] would replace any values in myarray with an empty
array.This specification defines the following mechanisms by which xRegistry servers can be discovered:
If access to the root of a hosting environment is available, then it is
RECOMMENDED that implementations leverage the
/.well-known discovery
mechanism
by making xRegistry "discovery" metadata available at the
following URL:
/.well-known/xregistry
If supported, a request (GET) to this location MUST return a document of
the form:
{
"registries": {
"URL", *
}
}
Where:
URL is the full absolute URL location an xRegistry server.While normally this list would only include xRegistry servers hosted on this specific host, it is not a requirement that this be the case.
{
"registries": [
"https://example.com/schemaregistry"
]
}
Similar to the Host-based Discovery mechanism, an xRegistry server instance MAY advertise a list of additional xRegistry servers by supporting a protocol-specific retrieval mechanism.
Regardless of the exact protocol mechanism, the data returned MUST adhere to the same format as the Host-based discovery mechanism:
{
"registries": {
"URL", *
}
}
Where:
URL is the full absolute URL location an xRegistry server.See the xRegistry HTTP specification for more information on the HTTP-specific discovery mechanism.
GET http://example.com/registries/dev/.xregistry
HTTP/1.1 200 OK
Content-Type: application/json; charset=utf-8
{
"registries": [
"https://example.com/registries/prod"
]
}
GET http://example.com/.well-known/xregistry
HTTP/1.1 200 OK
Content-Type: application/json; charset=utf-8
{
"registries": [
"https://example.com/registries/dev",
"https://example.com/registries/prod"
]
}
Since clients might not be aware of the hosting limitations of the servers, to maximize the set of xRegistries servers found, both Host-based and Registry-based mechanisms SHOULD be attempted.
Web pages MAY choose to advertise the location of a related xRegistry
server by including a <link> element in the page's <head> section.
The format of the element MUST adhere to:
<link rel="alternative" type="application/xregistry+json"
title="STRING" href="URL"/>
<link rel="alternative" type="application/xregistry+json"
title="Our xRegistry server" href="https://xreg.example.com/"/>
If an error occurs during the processing of a request, even if the error was
during the creation of the response (e.g. an invalid inline value was
provided), then an error MUST be generated and the entire request MUST be
undone.
In general, when an error is generated, it SHOULD be sent back to the client. However, this MAY not happen if the server determines there is a good reason to not do so - such as due to security concerns.
Each protocol binding specification will define how the error structure SHOULD be returned back to clients.
Each error definition consists of a set of fields as below:
| Field Name | Description |
|---|---|
| Type | REQUIRED. MUST be a URI to the error definition/specification. |
| Code | REQUIRED. MUST be the HTTP response code and status text. |
| Title | REQUIRED. MUST be a short (non-empty) human-readable summary of the error. This SHOULD be sufficiently detailed for most users to determine what is the cause of the error. See the text below about substitution strings. |
| Args | OPTIONAL. A map of the substitution strings that were used when generating the "Title" text. |
| Subject | OPTIONAL. If present, MUST a reference to the entity being processed when the error occurred. In the case of a Registry entity, it MUST be the XID of the entity. If no specific value is appropriate then this field MAY be excluded. MUST start with "/". |
| Detail | OPTIONAL. While "Title" conveys the critical error information, if additional details might be useful to users, such as hints as to how to fix the error, then this field SHOULD be used. |
| Instance | OPTIONAL. This non-empty string that can be used by servers to identify details related to the request/error processing. For example, a request or transaction ID of the request that generated the error. This information is not meant to be useful to clients directly, but can be provided to server administrators to help debugging if necessary. This specification places no striction on the format of this value. |
| Source | OPTIONAL. A non-empty string representing the component that raised the error. Similar to "Instance", this is not meant to be used by clients, rather it is for debugging purposes. |
The definition of each error's "Title" field MAY include substitutable
placeholders that allows for situational specific data to be included. Each
placeholder will be denoted as <...> in the "Title" text, where "..." MUST
be of the form [a-z][a-z0-9_]*, no longer than 63 characters, and
used as the key in the "Args" map. At runtime, each placeholder MUST be
replaced with the appropriate value from "Args", and "Args" (if non-empty)
MUST appear in the error structure returned to the client. As an optimization,
if "
HTTP response codes and status text are defined in the HTTP Semantics specification.
The "Type", "Code", and "Subject" values MUST be as specified in error's specification. The "Title" field MAY be modified as needed based on the context in which the implementation is running. This includes being specified in a language other than English, however it MUST still include the same substitution values (possibly in a different order).
In most user-facing scenarios, clients will only need to see the "Title" and "Detail" fields. The other fields are provided for either administrative purposes or to help enable 3rd party tooling.
Most of the error conditions mentioned in this specification will include a reference to one of the errors listed in this section. While it is RECOMMENDED that implementations use those errors (for consistency), they MAY choose to use a more appropriate one. Implementations MAY define additional extension fields, as well as new error definitions. For new errors, it is RECOMMENDED that the "Subject" value appears within the "Title" field, when appropriate.
While not a requirement, it is RECOMMENDED that custom errors adhere to the following rules for consistency:
Title and Detail text complete sentences that start with a capital
letter and end with a period.<subject> in Text so that end users only need to examine the
Title to know what went wrong and which entity was being processed.Group, Groups, Resources and Resource when
possible. Instead use the appropriate "singular" or "plural" type name for
the entity in question. End users will likely not know what "Groups" or
"Resources" are if they only work with the model defined entities.error_detail as the "Arg" name for substitution text that provides
more details about the error beyond the generic text provided by the
error definition itself.Examples:
An error serialized per the HTTP binding specification:
HTTP/1.1 400 Bad Request
Content-Type: application/json; charset=utf-8
{
"type": "https://github.com/xregistry/spec/blob/main/core/spec.md#bad_flag",
"title": "The specified flag (collections) is not allowed in this context: /schemagroups.",
"detail": "?collections is only allow on the Registry or Group instance level.",
"subject": "/schemagroups",
"args": {
"flag": "collections"
},
"instance": "123e4567-e89b-12d3-a456-426614174000",
"source": "parser:4123#d3beeeb5b0f"
}
The following list of protocol-independent errors are defined:
In the case of using the HTTP protocol binding, this error MUST include
the HTTP Allow header in the response indicating which HTTP methods
the API supports, if any.
https://github.com/xregistry/spec/blob/main/core/spec.md#action_not_supported405 Method Not AllowedThe specified action (<action>) is not supported for: <subject>.<request_path>action: The operation requested - e.g. PATCH in HTTP.https://github.com/xregistry/spec/blob/main/core/spec.md#ancestor_circular_reference400 Bad RequestFor "<subject>", the request would create a circular list of ancestors: <list>.<resource_xid>list: List of ancestor IDs in the circular list.https://github.com/xregistry/spec/blob/main/core/spec.md#bad_defaultversionid400 Bad RequestAn error was found in the "defaultversionid" value specified (<value>): <error_detail>.<request_path>value: The defaultversionid value specified.error_detail: Specific details about the error.https://github.com/xregistry/spec/blob/main/core/spec.md#bad_details400 Bad RequestUse of "$details" in this context is not allowed: <subject>.<request_path>https://github.com/xregistry/spec/blob/main/core/spec.md#bad_filter400 Bad Request<request_path>An error was found in "filter" value (<value>): <error_detail>.value: Offending "filter" value.error_detail: Specific details about the error.https://github.com/xregistry/spec/blob/main/core/spec.md#bad_flag400 Bad RequestThe specified flag (<flag>) is not allowed in this context: <subject>.<request_path>flag: The invalid flag name used.https://github.com/xregistry/spec/blob/main/core/spec.md#bad_ignore400 Bad Request<request_path>An error was found in "ignore" value (<value>): <error_detail>.value: Offending "ignore" value.error_detail: Specific details about the error.https://github.com/xregistry/spec/blob/main/core/spec.md#bad_inline400 Bad Request<request_path>An error was found in "inline" value (<value>): <error_detail>.value: Offending "inline" value.error_detail: Specific details about the error.This error is purposely generic and can be used when there isn't a more
condition-specific error that would be more appropriate. Implementations
SHOULD attempt to use a more specific error when possible. Notice, the Title
field is just a substitution value and MUST NOT be empty.
https://github.com/xregistry/spec/blob/main/core/spec.md#bad_request400 Bad Request<request_path><error_detail>.error_detail: Specific details about the error.https://github.com/xregistry/spec/blob/main/core/spec.md#bad_sort400 Bad Request<request_path>An error was found in "sort" value (<value>): <error_detail>.value: Offending "sort" value.error_detail: Specific details about the error.https://github.com/xregistry/spec/blob/main/core/spec.md#cannot_doc_xref400 Bad Request<resource_xid>Retrieving the document view of a Version for "<subject>" is not allowed because it uses "xref".https://github.com/xregistry/spec/blob/main/core/spec.md#capability_error400 Bad Request/capabilitiesThere was an error in the capabilities provided: <error_detail>.error_detail: Specific details about the error.https://github.com/xregistry/spec/blob/main/core/spec.md#capability_missing_value400 Bad Request/capabilitiesThe "<name>" capability needs to contain "<value>".name: The name of the capability missing a mandatory value.value: The missing "specversions" value.https://github.com/xregistry/spec/blob/main/core/spec.md#capability_unknown400 Bad Request/capabilitiesUnknown capability specified: <field>.field: The name of the unknown capability.https://github.com/xregistry/spec/blob/main/core/spec.md#capability_value400 Bad Request/capabilitiesInvalid value (<value>) specified for capability "<field>". Allowable values include: <list>.value: Unknown value.field: Capability field being modified.list: Comma separated list of allowable values.https://github.com/xregistry/spec/blob/main/core/spec.md#capability_wildcard400 Bad Request/capabilitiesWhen "<field>" includes a value of "*" then no other values are allowed.field: The capability field being modified.https://github.com/xregistry/spec/blob/main/core/spec.md#compatibility_unknown400 Bad Request<resource_xid>The compatibility value (<compat>) on Resource "<subject>" is not supported for format "<format>".compat: The Resource's meta.compatibility value.format: The Version's format value.https://github.com/xregistry/spec/blob/main/core/spec.md#compatibility_violation400 Bad Request<resource_xid>The request would cause one or more Versions of "<subject>" to violate its compatibility rule (<compat>).versionid values that would be in violation.compat: The Resource's meta.compatibility value.https://github.com/xregistry/spec/blob/main/core/spec.md#constraint_failure400 Bad Request<resource_xid>The request would result in one or more Versions of "<subject>" not being compliant with its owning Group's "equals" constraint for attribute "<path>".path: The dot (.) notion traversal path to the Resource's attribute being constrained.https://github.com/xregistry/spec/blob/main/core/spec.md#data_retrieval_error500 Internal Server Error<path>The server was unable to retrieve all of the requested data.https://github.com/xregistry/spec/blob/main/core/spec.md#defaultversionid_request400 Bad Request<resource_xid>Processing "<subject>", the "defaultversionid" attribute is not allowed to be "request" since a Version wasn't processed.https://github.com/xregistry/spec/blob/main/core/spec.md#extra_xref_attribute400 Bad Request<resource_xid>Attribute "<name>" is not allowed to be present since the Resource (<subject>) uses "xref".name: The name of the attribute in question.https://github.com/xregistry/spec/blob/main/core/spec.md#format_external400 Bad Request<version_xid>Version "<subject>" references a document stored outside of the Registry, therefore no validation was performed.https://github.com/xregistry/spec/blob/main/core/spec.md#format_unknown400 Bad Request<version_xid>Version "<subject>" has a "format" value (<format>) that it not supported.format: The Version's format value.https://github.com/xregistry/spec/blob/main/core/spec.md#format_violation400 Bad Request<version_xid>The request would cause Version "<subject>" to be non-compliant with its "format" (<format>).format: The Version's format value.https://github.com/xregistry/spec/blob/main/core/spec.md#groups_only400 Bad Request<request_path>Attribute "<name>" is invalid. Only Group types are allowed to be specified on this request: <subject>.name: The name of the attribute in question.https://github.com/xregistry/spec/blob/main/core/spec.md#hasdocument_violation400 Bad Request<version_xid>The request would cause Version "<subject>" to be non-compliant. The Resource model has "hasdocument" set to "false" but this Version has document content.https://github.com/xregistry/spec/blob/main/core/spec.md#inline_noninlineable400 Bad Request<request_path>Attempting to inline a non-inlineable attribute (<name>) on: <subject>.name: The name of the attribute in question.https://github.com/xregistry/spec/blob/main/core/spec.md#invalid_attribute400 Bad Request<entity_xid>The attribute "<name>" for "<subject>" is not valid: <error_detail>.name: Name of the attribute in question.error_detail: Specific details about the error.https://github.com/xregistry/spec/blob/main/core/spec.md#malformed_id400 Bad Request,<request_url>,The specified ID value (<id>) is malformed: <error_detail>.,id: The ID value that is malformed.error_detail: Specific details about what is wrong with the ID.https://github.com/xregistry/spec/blob/main/core/spec.md#malformed_xid400 Bad Request,<request_url>,The specified XID value (<xid>) is malformed: <error_detail>.,xid: The XID value that is malformed.error_detail: Specific details about what is wrong with the ID.https://github.com/xregistry/spec/blob/main/core/spec.md#malformed_xref400 Bad Request,<request_url>,The specified xref value (<xref>) is malformed: <error_detail>.,xref: The xref value that is malformed.error_detail: Specific details about what is wrong with the xref.https://github.com/xregistry/spec/blob/main/core/spec.md#mismatched_epoch400 Bad Request<entity_xid>The specified epoch value (<bad_epoch>) for "<subject>" does not match its current value (<epoch>).bad_epoch: The epoch value specified in the request.epoch: The current epoch value for the entity being processed.https://github.com/xregistry/spec/blob/main/core/spec.md#mismatched_id400 Bad Request<entity_xid>The specified "<singular>id" value (<invalid_id>) for "<subject>" needs to be "<expected_id>".singular: The "singular" name of the model entity being processed.invalid_id: The ID values specified in the request.expected_id: The ID that was supposed to be used instead.https://github.com/xregistry/spec/blob/main/core/spec.md#mismatched_version_attribute400 Bad Request<resource_xid>The request would cause the "<name>" attribute across the Versions of "<subject>" to be different.name: The dot (.) notation path to the attribute causing the violation.https://github.com/xregistry/spec/blob/main/core/spec.md#misplaced_epoch400 Bad Request<entity_xid>The specified "epoch" value for "<subject>" needs to be within a "meta" entity.https://github.com/xregistry/spec/blob/main/core/spec.md#model_compliance_error400 Bad Request/modelThe model provided would cause one or more entities in the Registry to become non-compliant.https://github.com/xregistry/spec/blob/main/core/spec.md#model_error400 Bad Request/modelThere was an error in the model definition provided: <error_detail>.error_detail: Specific details about the error.https://github.com/xregistry/spec/blob/main/core/spec.md#model_required_true400 Bad Request/modelModel attribute "<name>" needs to have a "required" value of "true" since a default value is provided.name: Model attribute name in question.https://github.com/xregistry/spec/blob/main/core/spec.md#model_scalar_default400 Bad Request/modelModel attribute "<name>" is not allowed to have a default value since it is not a scalar.name: Model attribute name in question.https://github.com/xregistry/spec/blob/main/core/spec.md#multiple_roots400 Bad Request<resource_xid>The operation would result in multiple root Versions for "<subject>", which is not allowed for "<plural>".plural: The "plural" Resource type of the Resource being processed.https://github.com/xregistry/spec/blob/main/core/spec.md#not_available400 Bad Request<capability_available_type>The requested data (<subject>) is not available.Note, this SHOULD only be used when the request was directed to an entity that does not exist. For cases where the target entity does exist, but there is an invalid attempt to reference one that doesn't, the unknown_id error SHOULD be used instead.
https://github.com/xregistry/spec/blob/main/core/spec.md#not_found404 Not Found<entity_xid>The targeted entity (<subject>) cannot be found.https://github.com/xregistry/spec/blob/main/core/spec.md#one_resource400 Bad Request<entity_xid>Only one attribute from "<list>" can be present at a time for: <subject>.list: Comma separated list of <RESOURCE>* attributes allowed.This is a fairly generic error, so if a more focused one (e.g. invalid_attribute) can be instead it, then it SHOULD be.
https://github.com/xregistry/spec/blob/main/core/spec.md#parsing_data400 Bad RequestThere was an error parsing the data: <error_detail>.error_detail: Specific details about the error.https://github.com/xregistry/spec/blob/main/core/spec.md#readonly400 Bad Request<entity_xid>Updating a read-only entity (<subject>) is not allowed.https://github.com/xregistry/spec/blob/main/core/spec.md#required_attribute_missing400 Bad Request<entity_xid>One or more mandatory attributes for "<subject>" are missing: <list>.list: A comma separated list of attributes that are missing.https://github.com/xregistry/spec/blob/main/core/spec.md#resources_only400 Bad Request<group_xid>Attribute "<name>" is invalid. Only Resource types are allowed to be specified on this request: <subject>.name: The name of the attribute in question.This error MAY be used when it appears that the incoming request was valid but something unexpected happened in the server that caused an error condition.
https://github.com/xregistry/spec/blob/main/core/spec.md#server_error500 Internal Server Error<request_path>An unexpected error occurred, please try again later.https://github.com/xregistry/spec/blob/main/core/spec.md#setdefaultversionsticky_false400 Bad Request<resource_xid>Setting "defaultversionsticky" to "true" is not allowed since "maxversions" is "1".https://github.com/xregistry/spec/blob/main/core/spec.md#sort_noncollection400 Bad Request<request_path>Can't sort on a non-collection result set. Query path: <subject>.https://github.com/xregistry/spec/blob/main/core/spec.md#too_large406 Not Acceptable<request_path>The size of the response is too large to return in a single response.https://github.com/xregistry/spec/blob/main/core/spec.md#too_many_versions400 Bad Request<request_path>When the "setdefaultversionid" flag is set to "request", only one Version is allowed to be specified in the request message.https://github.com/xregistry/spec/blob/main/core/spec.md#unknown_attribute400 Bad Request<entity_xid>An unknown attribute (<name>) was specified for "<subject>".name: The name of the attribute in question.Attempts to reference an unknown Group type MUST generate an error (unknown_group_type).
https://github.com/xregistry/spec/blob/main/core/spec.md#unknown_group_type400 Bad Request<entity_xid>An unknown Group type (<name>) was specified in "<subject>".name: The Group type name that cannot be found.See not_found as well.
https://github.com/xregistry/spec/blob/main/core/spec.md#unknown_id400 Bad Request<entity_xid>While processing "<subject>", the "<singular>" with a "<singular>id" value of "<id>" cannot be found.singular: The "singular" name of the type of entity being processed.id: The ID of the entity that cannot be found.Attempts to reference an unknown Resource type MUST generate an error (unknown_resource_type).
https://github.com/xregistry/spec/blob/main/core/spec.md#unknown_resource_type400 Bad Request<entity_xid>An unknown Resource type (<name>) was specified for Group type "<group>".group: The Group type name under which the Resource was expected.name: The Resource type name that cannot be found.https://github.com/xregistry/spec/blob/main/core/spec.md#unsupported_specversion400 Bad Request<request_path>The specified "specversion" value (<specversion>) is not supported. Supported versions: <list>.specversion: The xRegistry specification version specified in the request.list: A comma separated list of supported specification versions.https://github.com/xregistry/spec/blob/main/core/spec.md#versionid_not_allowed400 Bad Request<resource_xid>While creating a new Version for "<subject>", a "versionid" was specified but the "setversionid" model aspect for entities of type "<plural>" is "false".plural: The "plural" type name of the owning Resource.